


Using Knowledge Graphs and Large Language Models to Accelerate Software Delivery
While computers work well with structured data and well-defined algorithms, they are woefully inadequate to understand unstructured human language. Industry analysts estimate that 80% of the data is unstructured[i] in documents, emails, notes, and collaboration tools. Lately, audio and video recordings have exponentially increased post-pandemic and with the rise of remote working. Unstructured human language is probably the last unconquered bastion, which no longer seems impenetrable given the rise of Large Language Models (LLMs) combined with the already mature knowledge graphs.
Understanding knowledge graphs
Knowledge graphs allow us to represent the real world around us in “nodes and edges” or “entities and relationships.” They are the network of nodes or entities connected through relationships.
For the unstructured user stories, such as:
- User story 1: A customer wants to get a premium quote for her car insurance by providing her insurance details conveniently and cost-effectively.
- User story 2: The agent wants underwriters to provide quotes for her customers’ insured items seamlessly through a comprehensive, cost-efficient process.
- User story 3: The underwriter wants all the insured details and past claims history to provide the most optimum premium quote.
We can construct a structured knowledge graph for the user stories, as shown in Figure 1.
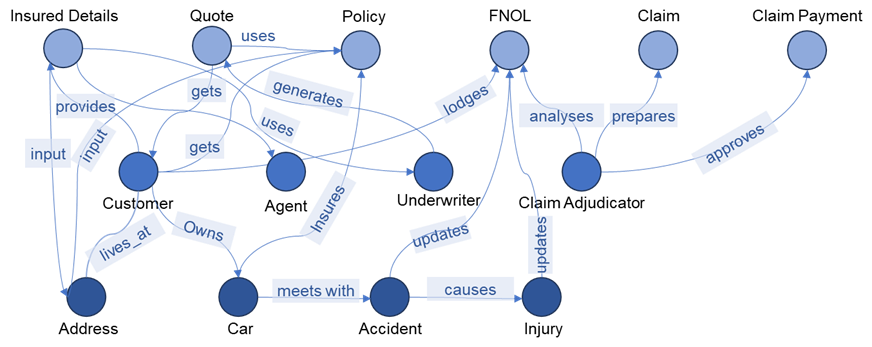
Figure 1: Scenario knowledge graph
Knowledge graph data models are easy to create. What you can create on a whiteboard, with circles or nodes and lines or edges, can be stored in your knowledge graph.
Knowledge graphs are excellent at representing the domain and, therefore are semantically rich. Yet coaxing information out of them needs complex query formulation and experts, hence the rather low industry adoption. Unlike relational databases, knowledge graphs are naturally suited for managing many interconnected data points. They capture complex relationships more easily than conventional databases.
What is a large language model?
A Large Language Model (LLM) is the new shiny toy that has taken the world by storm. Despite its many well-documented limitations, it can deliver jaw-dropping, coherent, and mostly accurate answers to queries posed in the normal colloquial English language. But they are pre-trained models, and getting relevant business-specific information is their Achilles’ heel. But suppose we can fine-tune LLMs with industry-, domain-, or company-specific knowledge graphs. In that case, we can provide a simplified search of context-specific information to the business users at their fingertips. Further, with the power of knowledge graphs and correlated data, business users can get the data lineage to make smarter and faster decisions.
For example, in the software development process, if we can correlate the “user story 1” to its test cases, code files to defects to product grooming audio files, as a software persona—a developer, tester, or architect—we can get an end-to-end view of the Software Development Life Cycle (SDLC) artifacts that allow better and smarter decisions.
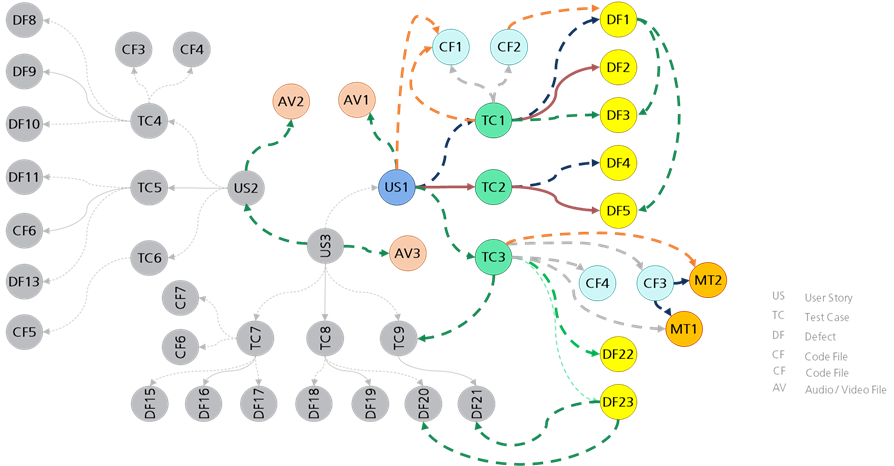
Figure 2: SDLC knowledge graph
Now, suppose we extend these knowledge graphs and correlations to other entities, such as the developer or tester who created the artifacts, the microservices associated with the source code files, and accreting call graphs generated by tools like CAST. In that case, it can trigger a host of potential productivity use cases in software development, as seen in Figure 3.
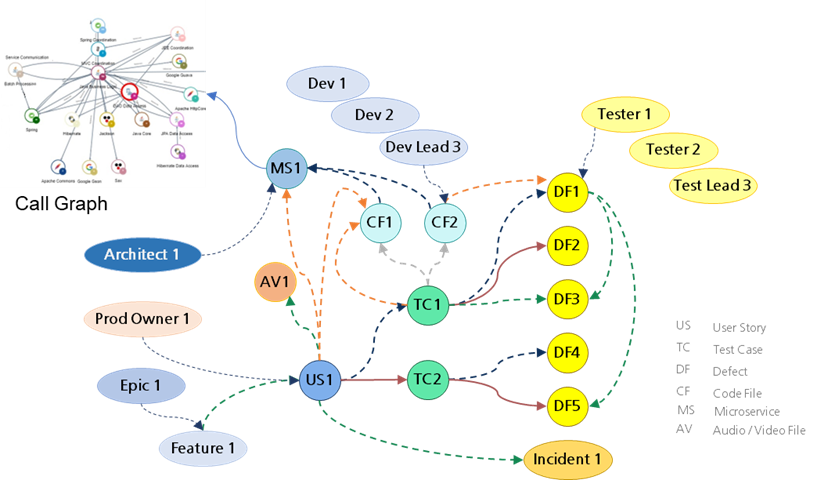
Figure 3: Correlated knowledge graph
Converting raw text to knowledge graph
The challenge is to convert unstructured data into structured. This traditionally includes extracting entities and determining the relationships between them.
A combination of an all-terrain tool trained on a humongous corpus of data, viz LLM, with a specific tool that codifies the knowledge of that domain, i.e., ontologies – make it a very potent combination. Employing ontologies can help LLMs better understand the semantics while extracting entities and relationships. And the resulting knowledge graph is much superior in terms of data quality.
What are ontologies?
Ontology provides the knowledge model for a particular domain and formally describes a knowledge base as a set of concepts or classes, its properties or attributes, relationships, and constraints. It provides a collection of controlled vocabularies arranged in a hierarchy. Every concept is clearly disambiguated through unique identifiers and are also linked to alternative synonyms or spellings in different languages. Importantly, ontologies make provision for providing relationships between the concepts that help link information together in different ways. Taxonomies, conversely, provide the actual instances of the classes or concepts, the relations between the class members, and the value of the properties or attributes.
Ontology-based LLM prompting to extract knowledge graphs can result in superior outcomes. One could postulate that it would be better to provide the context of entities and relations and make the LLM provide the graph in one shot. However, LLMs are good at single tasks. It is more efficient to approach the creation of knowledge graph in a sequence as we need output in a specific schema. It is better to first break down into a sequence of prompts to extract relevant entities or concepts. After that, we can introduce the relationships between the entities to complete the knowledge graph.
Smarter prompts are the key to LLMs. They must be constructed to focus on the specific entity you are trying to extract while ensuring that the LLMs do not hallucinate or provide additional superfluous entities as part of each outcome.
How to generate a knowledge graph?
Here are 6 steps to help you generate a knowledge graph from raw text and get relevant contextualized insights:
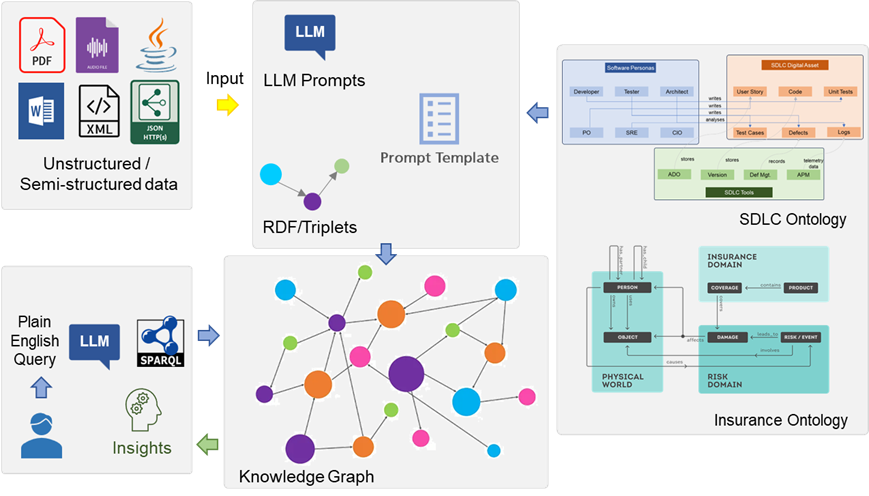
Figure 4: Knowledge graph generation steps
Step 1: Set up the ontology
Look at the available open-source ontologies and modify or update them to suit your purpose and use case. Or create one from the ground up, but this is an intensive exercise.
Step 2: Write ontology-driven prompts for LLM
Writing prompts enhanced by ontology that can provide the relevant triples for various entities and relationships while not hallucinating or returning irrelevant output is the key to success.
Step 3: Create a prompt template
Once the prompts are fine-tuned and delivering good outcomes, it will be good to create a prompt template repository to increase the chances of getting the right and complete set of triplets from the raw text.
Step 4: Create the graph database
Once triples are extracted, populate the knowledge graph in the graph database.
Step 5: Generate queries with LLMs
Graph database query creation needs a certain expertise. However, the business user can pose the query in plain English to help generate a query in SPARQL or any other declarative language, say Cypher, for the Neo4j graph database.
Step 6: Consume the insights
The query response will deliver relevant insights to the software personas to provide potential solutions for smarter and faster interventions.
Summary
Combining the complementary powers of LLMs, with ontology and knowledge graph can be a very potent approach to translating all the insight-rich unstructured SDLC assets into machine interpretable structured data. The best part is that the above process and the related concepts, are secular and can be extended across the industry domains.
Once we have insightful structured data extracted from the unstructured SDLC assets, we can deliver decision intelligence for software personas to make them smarter and faster.
For more insights visit Canvas by LTIMindtree
References
Research World, Possibilities and limitations, of unstructured data, Feb 20, 2023 Possibilities and limitations, of unstructured data (researchworld.com)
Blogger's Profile

Adish Apte
Principal Director- Product Engineering, Canvas by LTIMindtree
Adish leads the Canvas Platform in LTIMindtree. With over 25 years of IT industry experience, Adish brings strong experience across product management, relationship management, and sales. Apart from leading the Canvas Platform development, he uses innovation of AI/ML, particularly NLP, knowledge graphs, and ontology, to deliver new insights and accelerate software delivery.
More from Adish Apte
Sir Isaac Newton wisely once said, “If I have seen further, it is by standing on the shoulders…
Latest Blogs
Core banking platforms like Temenos Transact, FIS® Systematics, Fiserv DNA, Thought Machine,…
We are at a turning point for healthcare. The complexity of healthcare systems, strict regulations,…
Clinical trials evaluate the efficacy and safety of a new drug before it comes into the market.…
Introduction In the upstream oil and gas industry, drilling each well is a high-cost, high-risk…
