


Unlocking the Power of Snowflake Warehouses: Optimization Techniques for Data-driven Success
The quote “Data is the new oil,” attributed to Clive Humby, a British mathematician and entrepreneur, highlights the immense value of data in today’s world. Just as oil fueled the industrial revolution, data is fueling the digital revolution. However, with the vast amount of data being generated and collected, organizations need an effective solution. That’s where Snowflake’s Data Cloud Platform comes in.
Snowflake’s platform offers a range of services, including warehouses that allow users to process data or perform operations at breakneck speeds. Snowflake warehouses can be enlarged at any time to satisfy the requirements. This convenience comes at a price because Snowflake bases the pricing for its warehouses on a T-shirt sizing system.
Your company may process and analyze data rapidly and effectively while cutting expenses by optimizing your Snowflake warehouse. The primary optimization strategies for Snowflake warehouses will be covered in this blog post.
Setting warehouse type to Snowpark-optimized warehouses
Warehouses have specified memory per node to fetch the data from the database storage layer. But, when the queries require a large amount of data to be fetched from storage, data can spill to remote storage. That’s where Snowpark-optimized warehouses, which offer 16X more memory per node than regular warehouses, come into play.
It is advised to use Snowpark-optimized warehouses for workloads with high memory requirements. The cost for these warehouses is a key consideration when examining the performance against cost trade-offs.
A snowpark-optimized warehouse can be created as:
CREATE WAREHOUSE <NAME> WITH WAREHOUSE_SIZE = ‘<Anything greater than MEDIUM>’ WAREHOUSE_TYPE = ‘SNOWPARK-OPTIMIZED’;
Enable multi-clustering in the warehouse
Snowflake dynamically adds or removes clusters based on workload demand in the AutoScaleMode. When constructing or changing a warehouse, you can set the “MIN_CLUSTER_COUNT” and “MAX_CLUSTER_COUNT” parameters to enable AutoScaleMode.
To enable multi-clustering:
ALTER WAREHOUSE <NAME> SET MIN_CLUSTER_COUNT=2, MAX_CLUSTER_COUNT=10;
Increasing clusters directly impacts the cost, but controlling the same via Snowflake provides scaling policies. The Economy policy is suitable for workloads that are less time-sensitive and can accept higher latency. In contrast, the Standard policy is for applications that demand high performance and low latency.
- Standard (Default): When a query is queued, or the system determines that there is one more query to conduct, a new cluster is immediately added. After the first cluster has begun, the following clusters wait 20 seconds before initiating.
- Economy: Before establishing a new cluster, the algorithm predicts if there will be enough query traffic to keep the cluster active for at least 6 minutes.
The scaling policy can be set as follows:
ALTER WAREHOUSE <NAME> SET SCALING_POLICY = ‘<STANDARD/ECONOMY>’;
Enable auto-resume
Every warehouse that has auto-suspend enabled should also have auto-resume enabled. The warehouse must be explicitly enabled, and an error may arise if end users attempt to run the application or any specific queries on the warehouse without auto-resume.
To enable or disable auto-resume:
ALTER WAREHOUSE <NAME> SET AUTO_RESUME = ‘<TRUE/FALSE>’;
Enabling auto-suspend and setting an appropriate timeout for workloads
It’s recommended that all the warehouses should have auto-suspend enabled. However, picking the time for auto-suspend is quite difficult, and a wrong choice is often made.
Considerations:
- Decide on the auto-suspend time after determining the use case and how frequently the queries are executed. Auto-suspend can be set as:
ALTER WAREHOUSE <NAME> SET AUTO_SUSPEND = <NUM_IN_SECOND>;
Note: Providing 0 or NULL ensures that the warehouse never suspends.
- Additionally, you should never set the auto-suspend time to less than a minute, as the billing incurs for at least a minute once the warehouse is on before switching to a per-second charge. Set the right “STATEMENT_TIMEOUT_IN_SECONDS” for each warehouse after you have determined specific workload patterns to prevent any unexpected surcharges for any inaccurate or ineffective queries.
It can be set up as follows:
ALTER WAREHOUSE <NAME> SET STATEMENT_TIMEOUT_IN_SECONDS = <NUM_IN_SECONDS>;
All the methods are well known, yet they are underutilized in the real world. Apart from these, several other advanced techniques can be used to configure the warehouses optimally and maximize the usage of warehouses as per the costs. These need much work and expertise but can be accomplished easily by utilizing LTIMindtree PolarSled Govern FinOps. LTIMindtree, a Global Service Partner for Snowflake, has created this framework to maximize the usage of the Snowflake account. FinOps helps you to estimate, monitor, control, and optimize the environment. Let’s take a closer look at how we can leverage a few FinOps examples to uncover the potential of warehouses.
Identifying warehouse patterns or loads
The Warehouse-360 dashboard depicts warehouse load details that can be used to spot any recurring usage spikes for ongoing, queued, and queued-provisioning queries. If the queuing surges, as seen in Fig.1, occur frequently at predetermined intervals, you have two options:
- FinOps has an optimizer dashboard that the user can filter based on the warehouse and specific duration, identify the workloads contributing to the higher load, and move higher loads to different warehouses. This can assist you in correctly separating into warehouses by recognizing workload information, such as tables, to leverage caching under the same department or application.
- Once you have verified that workloads are of the same type, you can enable multi-clustering in the warehouse.
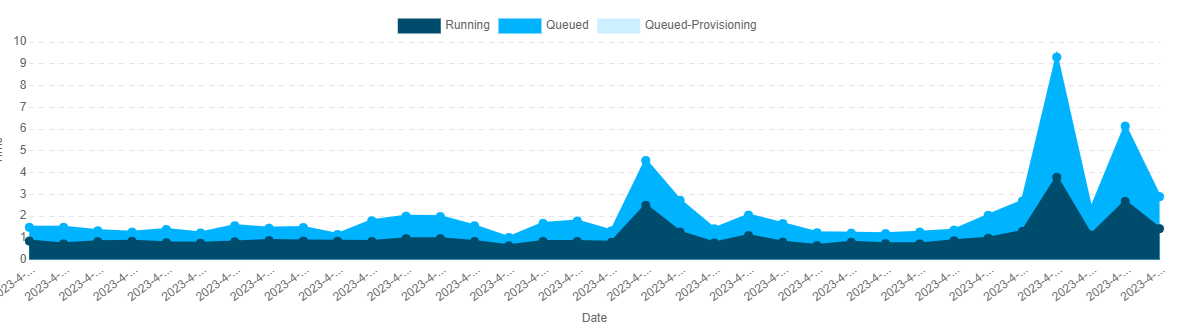
Fig.1. Warehouse Load
Selecting the correct size of the warehouse
Finding an ideal warehouse size can be a highly challenging task. Several approaches include running the same set of queries against different sizes or raising the size until performance stops improving or the Service Level Agreement (SLA) isn’t being violated. FinOps warehouse recommendation can assist you in correctly sizing the warehouse for a set of queries that suddenly take varied amounts of time.
To estimate the fit of present warehouse sizing and suggest a new warehouse size, the recommendation determines the queries being run on the specific warehouse, the time spent, coupled with the proportion of queries being executed, as shown in Fig.2. The cost per warehouse for that set of workloads, along with the new warehouse size, is highlighted in red if any recommendations need to be addressed.
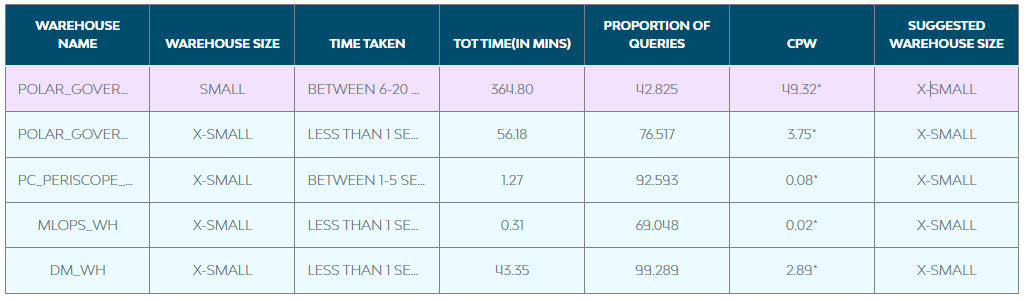
Fig.2. Warehouse Recommendation
Warehouse scheduler
As we saw in different scenarios above, a customer may want to leverage caching and have different workload patterns at different intervals with various complexities. That’s where the warehouse scheduler leverages the warehouse at its max potential ability using warehouse scheduler.
Let’s consider warehouse POLAR_GOVERN_WH runs workloads for BI reports and batch loading is done for incremental data on weekdays between 9 and 11. This should be run on SMALL sizing rather than the default X-SMALL size. Since incremental data also requires scanning existing partitions, it’s better to utilize a warehouse scheduler that will use the same warehouse with sizes specified per the intervals.
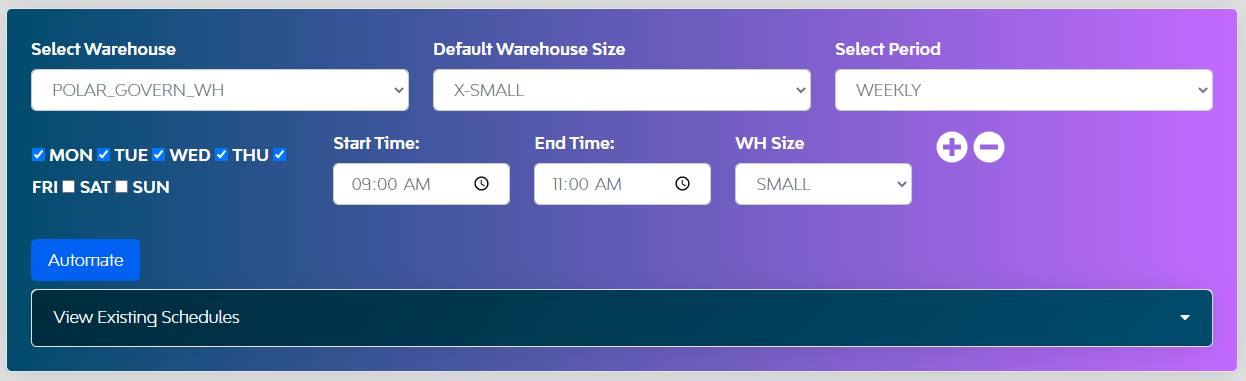
Fig.3 Warehouse Scheduler
These optimization methods can help you get the most out of your snowflake data cloud investment using the snowflake parameters or configurations and LTIM PolarSled Govern FinOps.
Instead of only utilizing the warehouse, LTIMindtree has integrated all their experience and knowledge into FinOps, which has considerably more potential features like Machine Learning (ML)-based dashboards, chargeback mechanisms, optimizing queries, and more. If you’re interested in knowing more, please talk to us.
Blogger's Profile

Jainam Soni
Senior Data Engineer, Snowflake COE, LTIMindtree
Jainam Soni is a senior Data Engineer with over 3.4 years of experience at LTIMindtree. He is currently involved in the development of the PolarSled Product as part of the Snowflake CoE team. Passionate about exploring new technologies and constantly expanding his knowledge, Jainam spends his weekends delving into various subjects and conducting in-depth research. He believes in the power of learning and is always eager to embrace new challenges.
Latest Blogs
A closer look at Kimi K2 Thinking, an open agentic model that pushes autonomy, security, and…
We live in an era where data drives every strategic shift, fuels every decision, and informs…
The Evolution of Third-Party Risk: When Trust Meets Technology Not long ago, third-party risk…
Today, media and entertainment are changing quickly. The combination of artificial intelligence,…
