


Unlocking the Power of Data Modernization with Scintilla: Migrating SAS Workloads to PySpark
In the ever-evolving data processing landscape, transitioning from traditional systems to modern platforms has become imperative. As organizations endeavor to stay ahead in the data-driven race, they look forward to migrating from Statistical Analysis Systems (SAS) to modern platforms like PySpark. As per a recent report by Prudent Markets, the Apache PySpark market size is expected to grow at a CAGR of 33.9%. However, this journey is not without its challenges. As businesses seek simplified solutions to navigate this transition seamlessly, tools like Scintilla emerge as game-changers in SAS modernization.
Understanding SAS and PySpark
SAS is a comprehensive software suite developed by the SAS Institute in 1976. It offers advanced analytics, business intelligence, and data management tools. It supports various data formats and provides statistical functions, machine learning algorithms, and data mining capabilities. SAS Visual Analytics facilitates interactive data visualization and reporting, serving diverse industries like healthcare, finance, manufacturing, and government. With its GUI and proprietary language, SAS ensures ease of use for users of all backgrounds.
PySpark, on the other hand, is an open-source library built on Spark that enables distributed computing and big data processing. Supporting multiple data sources, including CSV and databases, PySpark offers tools like RDDs, DataFrames, and MLlib for machine learning tasks. It finds applications across industries and boasts ease of use with its Python interface and Jupyter Notebook support. Both SAS and PySpark cater to diverse analytics needs, with SAS excelling in user-friendliness and PySpark excelling in open-source flexibility and scalability.
Why modernize from SAS to PySpark?
Modernizing from SAS to PySpark offers several advantages for organizations looking for a competitive edge in the data-driven landscape. PySpark is an open-source library for distributed computing and big data processing. Its rich set of tools for data processing, analysis, and machine learning makes it a popular choice for data scientists and engineers working with large datasets. PySpark’s ease of use, interactive data analysis capabilities, and support for various data sources make it a versatile tool for big data analytics.
Challenges in SAS to PySpark Migration
Migration from SAS to PySpark involves several challenges, ranging from technical hurdles to organizational constraints. Here are some common issues encountered during the migration process:
1. Legacy systems and codebase
Extensive legacy systems built on SAS may include complex codebases, data structures, and dependencies. Migrating these systems to PySpark requires careful planning and consideration to ensure compatibility and minimize disruptions.
2. Coding style variations
Developers have unique coding approaches, leading to style variations across the project. Addressing this challenge is essential to ensure code quality, readability, and long-term maintainability of the analytics solution.
3. Functional differences
SAS functions and macro functions used in the underlying database may behave differently and produce different results in a PySpark environment. This requires converting SAS functions to their PySpark equivalents.
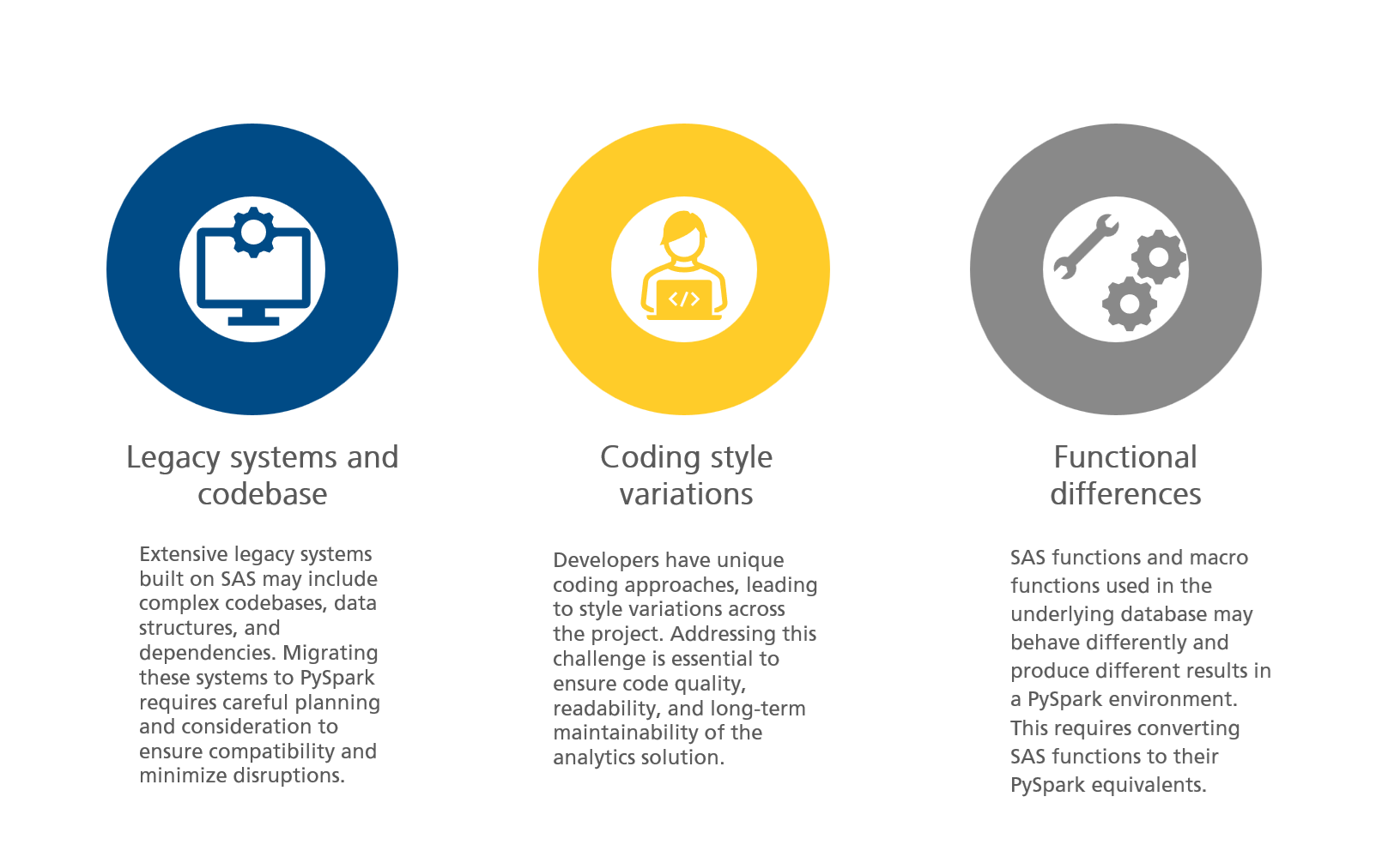
Figure 1: Challenges in SAS to PySpark Migration
Simplifying SAS modernization with Scintilla
LTIMindtree’s Scintilla is an innovative tool designed to support the SAS to PySpark workload migration. We have designed the tool to eliminate the requirement for code migration and testing in process migration. It provides a user interface for uploading SAS files to generate files compatible with PySpark. Scintilla scans SAS programs to identify individual statements or procedure blocks and converts them into equivalent Spark SQL statements or DataFrame functions.
Our tool simplifies the modernization of data processing workflows for organizations. It offers automated code conversion and seamless integration capabilities. Additionally, Scintilla provides comprehensive data transformation tools and built-in measures for regulatory compliance.
How Scintilla works
Scintilla offers automated code conversion of SAS input to PySpark-compatible output. Its user-friendly interface and workflow demonstration make it easy for organizations to navigate the migration journey, ensuring a smooth transition from SAS to PySpark. The following infographic illustrates the various components of the tool.
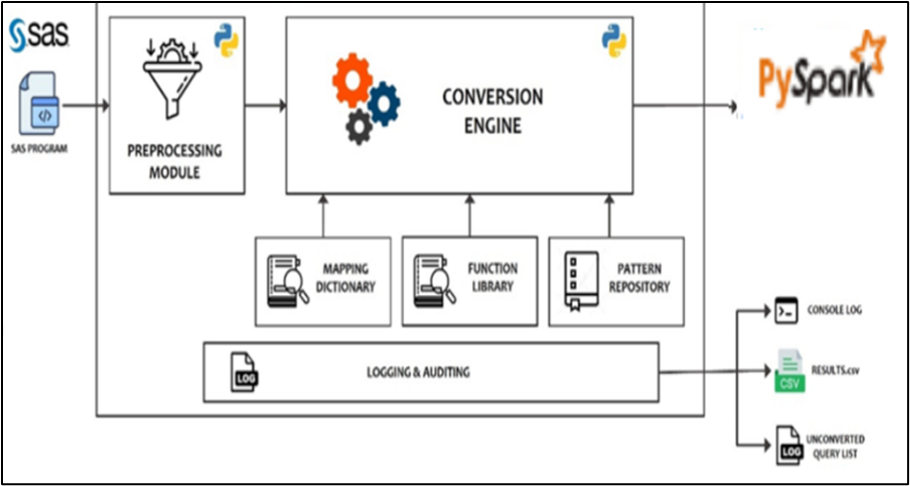
Figure 2: Tool components
Pre-processing module
A preprocessing module standardizes its format to handle diverse coding styles in SAS programs by addressing issues like missing quit/run statements and varied macro programming styles. This module reads SAS programs, standardizes their format, and creates sanitized versions in a separate directory. This ensures accurate identification of code blocks and prevents exceptions during conversion.
Conversion engine
This is the core of the tool, managing the conversion of SAS code to PySpark. The process involves:
- Processing each file in the cleansed programs directory individually
- Scanning programs to identify code blocks for conversion, skipping system-generated variables and macros
- Checking identified code blocks against the pattern repository
- Utilizing Scintilla conversion engine for search and replace based on the repository
- Printing converted code blocks along with comments and handling exceptions
- Generating a log file for skipped or exception-prone code blocks
Mapping dictionary
The mapping dictionary catalogs PySpark equivalent keywords and SQL functions for those found in SAS programs, including SAS and SQL keywords/functions.
Function library
The function library is akin to the mapping dictionary but handles complex scenarios beyond simple keyword replacement. It contains Python code for generating PySpark equivalents of SAS functions.
Pattern repository
The pattern repository catalogs supported SAS patterns for conversion, aiming to convert as many as possible to PySpark. However, PySpark’s technical limitations necessitate the identification of boundary constraints to ensure feasibility.
Logging and audit module
The logging and audit module creates process and exception logs during conversion and generates a log file listing encountered exceptions. At the end of the conversion, it produces four files: a converted PySpark file, a converted PySpark notebook file, a results file summarizing conversion details for each SAS input file, and a lineage summary that includes Metadata of the source and target system data objects referred to in a SAS Code.
Why Scintilla?
Scintilla is a one-of-a-kind tool for SAS to PySpark conversion. Several reasons make it unique and extremely useful:
- It is the only accelerator that automatically converts the SAS code without NLP algorithms, machine learning, deep learning, or Gen AI models.
- Built using Python, Scintilla analyzes and converts code and generates lineages between the input and the output.
- The tool does not require any additional or special hardware.
- It is platform independent, which means it can run on any platform.
- It is built for integration with Databricks and other PySpark platforms.
Conclusion
In conclusion, the transition from traditional systems like SAS to modern platforms such as PySpark is essential for organizations striving to maintain a competitive edge in today’s data-driven landscape. The journey involves numerous challenges, including managing legacy systems, addressing coding style variations, and converting functional differences. Tools like LTIMindtree’s Scintilla offer a streamlined and efficient solution. Scintilla’s innovative approach, leveraging automated code conversion and user-friendly integration, simplifies the migration process, enabling organizations to harness the power of PySpark’s scalability and flexibility without extensive manual re-coding. By facilitating a seamless transition, our tool empowers businesses to modernize their data processing workflows effectively, ensuring they remain at the forefront of technological advancement and data analytics.
Reference
Apache Spark Market Analysis, Revenue, Price, Market Share, Growth Rate, Forecast To 2030, LinkedIN, March 4, 2024: https://www.linkedin.com/pulse/apache-spark-market-analysis-revenue-price-epdtf/
Blogger's Profile

Ramesh Vanteru
Principal & Head of SAS COE
Ramesh is a SAS SME with close to two decades of experience in architecting and building data & SAS analytical applications. He is SAS Advanced Certified and a Snowflake SnowPro certified Architect providing technical advisory on building SAS and Snowflake data platforms with deep expertise in consulting, Taxation, BFSI, healthcare and implementation of Cloud Data Platforms.
More from Ramesh Vanteru
Latest Blogs
Core banking platforms like Temenos Transact, FIS® Systematics, Fiserv DNA, Thought Machine,…
We are at a turning point for healthcare. The complexity of healthcare systems, strict regulations,…
Clinical trials evaluate the efficacy and safety of a new drug before it comes into the market.…
Introduction In the upstream oil and gas industry, drilling each well is a high-cost, high-risk…
