


Multi-Cloud Analytics with BigQuery Omni – Making Sense of Multitenant Data
Data insights increasingly drive enterprises and businesses, and a data warehouse, a central repository of integrated data from within all organization functions, is central to enterprise data strategy. According to industry research firm CRN, 90% of organizations have a multi-cloud strategy, which complicates data integration, orchestration, and governance. With multi-cloud and hybrid-cloud becoming accepted, it is imperative to manage cross-analytics across cloud providers while building and running enterprise solutions in the cloud. However, providers unintentionally create data silos that cause data analysts to struggle.
These days predictive analytics is increasingly gaining adoption to populate real-time dashboards, perform ad hoc queries, and provide decision-making guidance. As businesses thrive digitally, data and analytics teams must collaborate across organizational boundaries to better understand their data through multi-cloud data warehouses, such as BigQuery Enterprise Data Warehouse.
Because of these business requirements for advanced analytics, and an emerging trend towards cost control, agility, and self-service data access, organizations are migrating to cloud-based data warehouses such as Google Cloud Platform (GCP) BigQuery.
GCP BigQuery Omni is a multi-cloud analytics service that enables businesses to break down data silos by securely and cost-effectively analyzing data across clouds. Google BigQuery Omni is an essential component to the rapidly growing list of businesses that are migrating their existing enterprise data warehouses from legacy technology stacks to Google Cloud. In October 2021, Google Cloud BigQuery Omni announced its support and interoperability with other leading cloud technology companies, including AWS and Microsoft Azure, providing end-to-end cross-cloud data analytics.
This blog will take you on a tour of BigQuery, a serverless, highly scalable, low-cost enterprise data warehouse on Google Cloud. Businesses can focus on data analysis to produce valuable insights using well-known SQL because there is no infrastructure to manage.
Google Cloud BigQuery aims to develop a data platform that supports tried-and-tested data technologies while offering cutting-edge capabilities and utilizing the many fantastic cloud technologies that are now accessible. For instance, Google’s BigQuery is a state-of-the-art serverless computing architecture that separates computing from storage. This gives data developers design and deployment flexibility and enables different layers of the architecture to function and scale independently. One of the few databases that support geospatial analysis and native machine learning is BigQuery.
Thanks to Pub/Sub, Dataflow, Bigtable, AI Platform, and third-party integrations, BigQuery can interact with conventional and innovative systems at various throughputs and latencies. In addition, it supports federated queries, columnar optimization, and ANSI-standard SQL, all of which are essential for the self-service, ad-hoc data exploration that users demand.
Google BigQuery Omni Google BigQuery Omni architecture for data processing
Google BigQuery is a serverless, highly scalable data warehouse with an integrated query engine. The query engine can execute SQL queries against TeraBytes (TB) of data in seconds and PetaBytes (PB) in minutes. Additionally, achieving this performance of Google BigQuery Omni doesn’t require you to manage any infrastructure or create/rebuild indexes.
You can start analyzing 2.2 billion things and compute/summarize them down to 20k in one minute, tweeted a Spotify Engineer.
BigQuery’s scale and speed are just two of its distinguishing characteristics.
Companies are increasingly embracing data-driven decision-making and fostering an open culture in which data within the organization is not siloed within departments. BigQuery contributes significantly to increasing innovation by providing the technology means that affect a cultural shift toward agility and openness. For instance, Twitter announced on its blog that it could democratize data analysis with BigQuery by making some of its most frequently used tables available to Twitter employees from various teams (marketing, engineering, and finance were mentioned).
Google BigQuery Omni – Serverless and Distributed SQL Engine
What if you could execute SQL queries just like in a Relational Database Management System (RDBMS) system and get MapReduce style efficient and distributed traversal of the entire dataset without worrying about infrastructure management? That third choice is what makes BigQuery so entrancing.
Working with BigQuery Enterprise Data Warehouse
As a data warehouse, BigQuery implies a significant degree of centralization and widespread use. The query, in general, uses one dataset. However, when we combine datasets from different sources or run queries against data that is kept outside BigQuery, the advantages of BigQuery become even clearer .
What does it mean in an enterprise context to be able to share and query across datasets? The organizations’ various departments can store their datasets in BigQuery and share the information with other departments and even with partner organizations quite easily.
Extract, Transform, Load vs. Extract Load vs. Extract Load Transform
In the conventional method of working with data warehouses, raw data is extracted from the source, transformed, and then loaded into the data warehouse. This complete end-to-end process is an Extract, Transform, and Load (ETL). BigQuery has a native, incredibly effective column storage format that makes ETL a smarter solution. The data pipeline extracts the necessary bits from the raw data (streaming data or batch files), typically written in either Apache Beam or Apache Spark. The extracted data is then transformed by BigQuery, including necessary cleanup or aggregation before delivering.
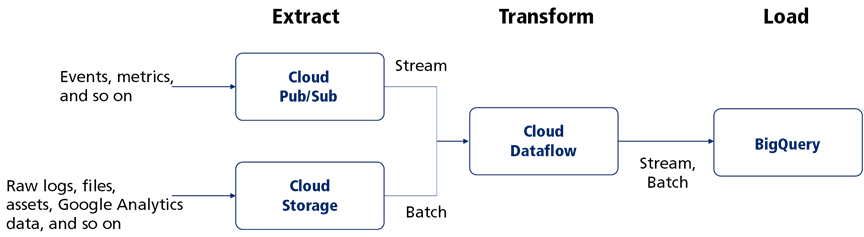
Figure: Architecture for Extract, Transform, Load (ETL) into BigQuery uses Cloud Dataflow-based Apache Beam pipelines to manage both streaming and batch data with the same code.
BigQuery’s ability to separate compute from storage allows for the federated querying of CSV (or JSON or Avro) files that are stored directly on Google Cloud Storage using BigQuery SQL queries. Federated queries can extract data from Google Cloud Storage using SQL queries, transform that data within those SQL queries, and then materialize the results into a BigQuery native table.
BigQuery can directly ingest common file formats into its native storage without the need for transformation—an Extract and Load (EL) workflow at will. The data should be loaded into the data warehouse because native data storage offers the best querying performance.
If possible, it is advised that the design is for an EL workflow rather than an ETL workflow. Switch to the ETL only if necessary. If possible, keep the entire ETL pipeline inside BigQuery and perform those transformations in SQL. Build an Apache Beam pipeline and have it executed in a serverless manner using Dataflow if the transformation is challenging to implement solely in SQL or if the pipeline requires streaming the data ingested in BigQuery as it arrives. Implementing ETL pipelines in Beam/Dataflow has the additional benefit of better integrating with Continuous Integration (CI) and unit testing systems since this is programmatic code.
BigQuery also enables an Extract, Load, and Transform (ELT) workflow in addition to the ETL and EL workflows. The plan is to load and extract the raw data in its current state and then rely on BigQuery views to transform it automatically. An ELT workflow is especially helpful when the raw data’s schema is in flux. For instance, one could still conduct exploratory research to see if a specific timestamp needs to be adjusted for the local time zone. The ELT workflow is helpful for prototyping and enables a company to begin concluding the data without having to act prematurely and potentially irrevocably.
Summary
Cross-cloud analytics, transfer, and authorized external tables will be an added advantage in 2023 to help data analysts drive governed, cross-cloud scenarios and workflows directly from the BigQuery interface. Cross-cloud analytics and transfer assist in moving the data required to complete data analysis in Google Cloud and discover insights by leveraging the unique capabilities of BigQuery Omni. Authorized external tables will provide consistent and fine-grained governance for your data, including row- and column-level security. When combined, these capabilities will enable simplified and secure cloud access for all our analytics requirements.
Blogger's Profile

Farhan Qureshi
Senior Specialist - Field Marketing Cloud – Google Cloud and Microsoft Azure, LTIMindtree
Farhan is a marketing professional supporting digital marketing initiatives across the cloud practice. With an MBA in Marketing, he engages in go-to-market initiatives from a strategic account penetration perspective. He designs, executes, and implements field marketing campaigns. He works closely with marketing managers and the sales team to promote lead generation and upsell opportunities.
More from Farhan Qureshi
Many IT leaders worldwide foresee the cloud transformation journey as a continuous evolution…
Latest Blogs
Core banking platforms like Temenos Transact, FIS® Systematics, Fiserv DNA, Thought Machine,…
We are at a turning point for healthcare. The complexity of healthcare systems, strict regulations,…
Clinical trials evaluate the efficacy and safety of a new drug before it comes into the market.…
Introduction In the upstream oil and gas industry, drilling each well is a high-cost, high-risk…
