


Harnessing the Power of Graph RAG Implementation for Smarter Data Insights
Introduction to RAG
To truly understand Graph RAG implementation, it’s essential to first explore RAG (Retrieval-Augmented Generation) and how it works. RAG enhances a large language model (LLM) by providing it with external knowledge retrieved from a knowledge database, enabling it to generate more accurate and contextually relevant responses. However, RAG’s dependency on vector databases often limits the richness of the contextual understanding in its responses. This is where Graph RAG steps in, by integrating graph machine learning with LLMs to elevate this approach further.
Unlike traditional RAG, which uses vector databases like Pinecone for information retrieval, Graph RAG organizes data into a knowledge graph. This graph-based approach enables a more holistic understanding of relationships, allowing for richer responses by leveraging community detection and graph traversal. This blog compares a traditional Pinecone-based RAG model and a Graph RAG model, highlighting their impact on query responses and the benefits of community-aware retrieval.
Traditional RAG Using Pinecone
In a standard RAG setup, data is split into chunks, converted into embeddings, and stored in a vector database like Pinecone. When a query is submitted, it is encoded into a vector and used to search for similar chunks in the database. The retrieved chunks are then fed into the LLM to generate a response.
In this article, Pinecone and a Graph database were populated with Wikipedia data about Queen Elizabeth I. Here’s how the Pinecone-based RAG implementation worked:
Pinecone is used as the vector database to store and retrieve document embeddings
- Sentence transformers encode both the query and documents into vector formats
- A similar search is conducted against Pinecone to fetch the top results, which are passed to the RAG model to generate an answer.
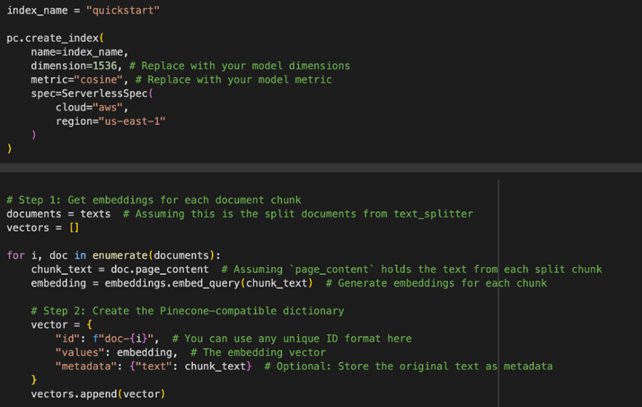
Diagram 1: Code for Vector RAG Search
While this approach is efficient, it has certain limitations in terms of contextual understanding and scalability. Let’s now look at how Graph RAG resolves these issues.
How Graph RAG Works
Graph RAG takes a different route by leveraging knowledge graphs in AI. This graph represents entities as nodes and their relationships as edges, creating an interconnected web of information. The knowledge graph is then used during query time to provide more holistic responses. Additionally, community detection algorithms, such as Leiden, partition the graph into clusters of closely related nodes, which can be leveraged for more structured and accurate information retrieval.
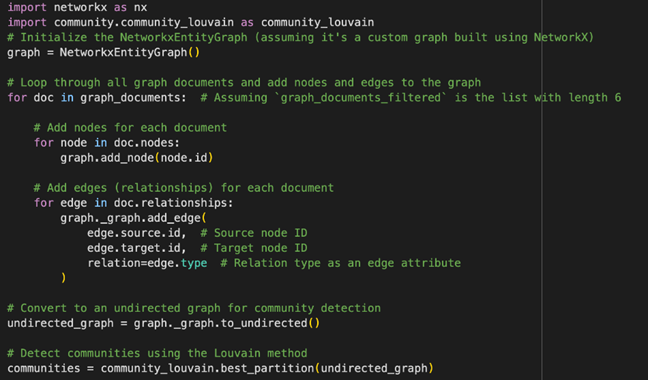
Diagram 2: Code for Graph RAG
Let’s break down the Graph RAG implementation
- Building the Graph: Nodes represent entities (e.g., people, places, objects), while edges define their relationships. For example, a node could be Queen Elizabeth I, and edges could represent her contributions to various countries.
- Community Detection:Algorithms like Louvain or Leiden group closely related nodes into clusters. For instance, one cluster could focus on Queen Elizabeth I’s cultural impact, while another might detail her political achievements.
- Summarization: Once communities are detected, an LLM (via LangChain) is used to generate community summaries, which capture the essential knowledge about the entities in each community.
- Query Handling: Upon receiving a query, the system retrieves the most relevant community summaries, appends them to the query, and feeds this enriched context into the LLM for a response.
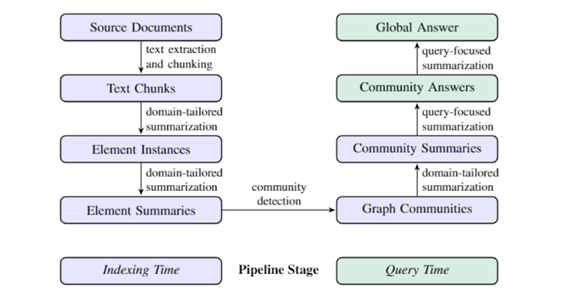
Diagram 3: Architecture of a Graph RAG Model
Comparison of RAG with Pinecone Vs. Graph RAG
How do these two approaches compare? Let’s explore:
- Contextual Understanding
- Pinecone RAG: Uses isolated text chunks for retrieval, which can miss nuances in relationships between entities.
- Graph RAG: Leverages the entire structure of the knowledge graph, allowing the system to understand connections and generate richer, more informed answers.
- Scalability
- Pinecone RAG: As the corpus grows, it may become difficult to capture all relevant information, especially when it’s spread across multiple documents.
- Graph RAG: By detecting communities and understanding relationships, it scales better with larger datasets, providing more organized knowledge retrieval.
- Accuracy
- Pinecone RAG: May struggle with fragmented information spread across different chunks.
- Graph RAG: Delivers more accurate answers by assembling information from related entities and communities.
For example, when asked, “What can you tell me about Queen Elizabeth I’s impact on her community?”, the differences are stark.
Graph RAG response

The response from a Graph RAG model is accurate and concise, prompting that it is superior in understanding connections and providing richer answers.
Pinecone Vector RAG response
While Pinecone offers a well-rounded historical overview of Queen Elizabeth I’s life, the information is more general, and lacks focus on specific communities or individuals. On the other hand, Graph RAG’s response zeroes in on Elizabeth I’s direct influence on her community, particularly on her role in art, culture, and religious development. This localized focus on her directly impacts within specific spheres, making it more contextually rich for community-centric questions.

The answer retrieved from Vector RAG is very elaborate and has drawn its context from multiple interrelated chunks but has missed the nuances in connections.
An Alternative Hybrid Approach
What if you could combine the best of both worlds? A hybrid approach merges the precision of knowledge graphs in AI with the breadth of vector database search.
Here’s how it works:
- Entities and relationships in the knowledge graph are embedded into a vector space.
- Queries are processed through both structured graph relationships and unstructured vector searches.
- The results are combined into a unified response, blending detailed entity relationships with broader contextual information.
This method enhances retrieval quality by integrating structured knowledge with the flexibility of vector-based systems, striking a balance between precision and comprehensiveness.
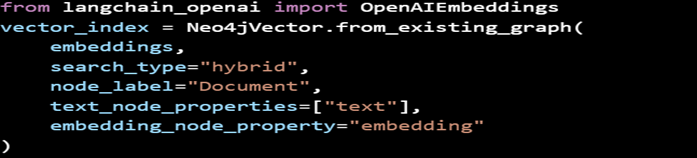
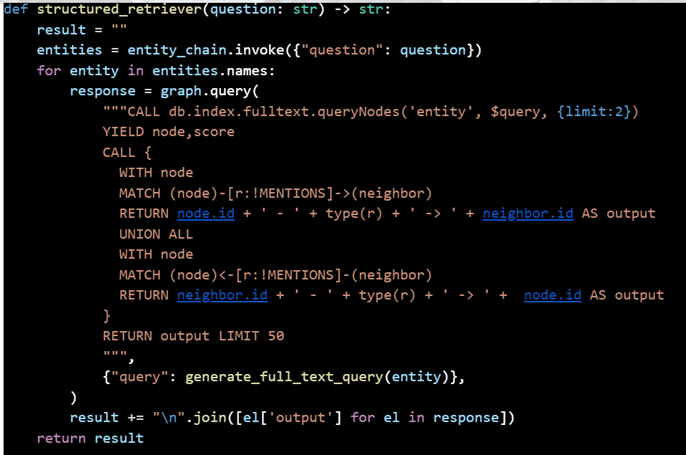
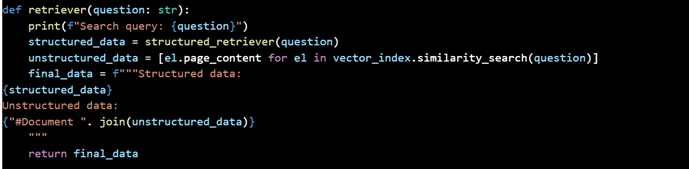
Diagram 4: Code for the Alternative Approach of Combining Vector RAG with Knowledge Graphs
Vector RAG vs. Graph RAG
| Feature | Vector RAG | Graph RAG |
| Search Type | Semantic search, similarity search | Graph traversal, relationship-based queries |
| Data Complexity | Well-suited for diverse, complex data | Optimized for data with intricate relationships |
| Cost | Cheaper | Expensive |
| Use Cases | Vast amounts of unstructured or semi-structured data, such as customer support chatbots, content recommendation systems, and information retrieval platforms. | Healthcare, finance, sophisticated risk assessment, fraud detection systems and scientific research, where complex, interconnected data is prevalent and domain-specific knowledge is essential. |
Further Refinement and Finetuning
- Evaluate factual knowledge: Test the language model’s performance on knowledge-intensive tasks such as question answering and fact verification.
- Assess reasoning capabilities: Evaluate performance on tasks requiring complex reasoning or logical inference.
- Ensure consistency: Analyze the coherence and non-contradictory nature of responses based on the integrated knowledge graph.
Address ethical considerations such as:
Audit the knowledge graph regularly for biases in entity representation, relationships, and attribute coverage
Implement techniques to balance and diversify the content of the knowledge graph
- Establish monitoring and feedback systems: Continuously collect feedback and refine the system for improvement.
Prospects and Conclusion
The future of Graph RAG implementation is full of exciting possibilities. Research opportunities include integrating multi-modal information into knowledge graphs, exploring the potential of quantum computing for graph algorithms, developing techniques for querying and reasoning over distributed, federated knowledge graphs, investigating deeper integrations between neural models and symbolic reasoning systems, advancing dynamic and temporal knowledge graphs, enhancing knowledge graphs with commonsense knowledge, and further developing techniques for creating and querying cross lingual and multilingual knowledge graphs to promote more globally inclusive AI systems.
Knowledge graphs excel in answering complex, multi-step queries that require deeper reasoning. This is particularly valuable when dealing with questions where the user’s context or background knowledge is essential to the answer.
Queries in Graph databases can achieve O(log(n)) or O (1) complexity for traversals as compared to O (n) in traditional document-based searches, which can lead to 50-70% reduction in query-time processing. Another benefit is that it improves the retrieval accuracy by 20-30% as queries are tailored to the graph structure.
For instance, a travel platform can leverage a knowledge graph to enhance search results. By combining a vector database of destinations with a knowledge graph of user travel history, the platform can accurately filter out previously visited locations. Additionally, incorporating factual data like geography and climate into the knowledge graph can improve the reliability of search results, reducing dependence on semantic search and language models.
All in all, Graph RAG implementation represents a transformative step in leveraging knowledge graphs in AI, offering a deeper understanding of relationships and significantly improving retrieval accuracy and efficiency. By combining the precision of graph traversal with the flexibility of vector databases, it opens doors to richer, context-aware responses and new possibilities across diverse industries. The journey ahead promises innovations that will continue to shape the future of intelligent, interconnected systems.
Citations
1) Graph RAG vs Vector RAG: a comprehensive tutorial with code examples, David Richards, 2024
3) Intro to Graph RAG, Neo4J, Dec 2024
4) Graph Structure Design for AI-Powered Graph RAG Systems: A Comprehensive Guide,2024
5) Graph RAG: Enhancing Retrieval-Augmented Generation with Graph Structures, Sahitya Arya, 2024
Blogger's Profile
Prarthana Poojara
Data Scientist, Enterprise AI, LTIMindtree
Prarthana is an accomplished professional with expertise in Python, Machine Learning, Generative AI, Data Science, and Neural Networks, complemented by a background in Aerospace Engineering. As a key member of the Azure Center of Excellence (CoE) at LTIMindtree, she focuses on integrating Generative AI with organizational accelerators. Prarthana collaborates with clients to deliver Azure solutions while continually exploring emerging Azure technologies to drive innovation and value.
Latest Blogs
The energy and anticipation were evident even before entering the arena, and attendees had…
A tectonic shift in wealth is underway, and agility is the key factor that will distinguish…
Educational institutions are at a crossroads where their future hinges on a single question:…
In times of market unpredictability, alternative investments offer a valuable advantage by…
