


Harnessing Predictive Power: BigQuery ML for Data Engineers
Picture this: a data engineer, whose forte lies in the intricacies of pipelines and databases, is tasked with delving into the world of analytics. Sounds like a fish out of water, right? Well, not quite. Enter BigQuery ML (BQML), a game-changer in the realm of machine learning that is turning the tables on traditional barriers to entry.
As a data engineer by trade, analytics isn’t my bread and butter. But with BQML, diving headfirst into the world of predictive modeling and data analysis suddenly feels like a breeze. Gone are the days of struggling through complex ML frameworks and obscure programming languages. With BQML, tapping into machine learning is a natural extension of my data engineering expertise.
Join me on a journey through my recent foray into BQML. We’ll explore how data engineers like me can harness the power of machine learning to drive insights and innovation. From integrating BQML seamlessly into a FinOps dashboard on Google Cloud Looker to unraveling the mysteries of financial data, we’ll uncover how this accessible, yet potent tool is revolutionizing the way we approach analytics.
My task was straightforward—predict the costs of various Google Cloud resources based on historical expenditure data. Armed with a BigQuery table filled with information on project names, service names, usage dates, and corresponding costs, I tackled this challenge using BigQuery ML. The pragmatic goal was to streamline budget planning and resource allocation by forecasting future expenses.
Choosing the right model was key. Do we stick with a simple linear regression, or does the data warrant a more sophisticated approach? BQML offered an array of options, from tried-and-tested methods like linear regression to more specialized techniques like time series forecasting.
In the following sections, I will explain the nuts and bolts of our approach, sharing the challenges we faced, the decisions we made, and the lessons we learned along the way. There are no grandiose promises or lofty ambitions—just a practical exploration of how BQML helped us tackle FinOps head-on.
Tackling the FinOps challenge: Predicting Google cloud costs
Initially, tackling our expenditure data with linear regression seemed like a maze. The thought of breaking it down by project-service groups before applying regression felt like a mountain to climb. But, true to developer form, I could not resist the urge to find an easier way.
Eventually, I stumbled upon boosted tree regression, a method that seemed to blend the best of classification and regression techniques. In this method, a series of decision trees are built sequentially, with each subsequent tree aiming to correct the errors made by the previous ones.
In the quest to build our boosted tree regression model, I journeyed through the dense thicket of documentation, seeking out the syntax and parameters crucial for success. However, being relatively green in this terrain, I leaned heavily on GPT to decode the nuances of each parameter and its role in shaping our model. Suffice it to say, GPT proved to be an invaluable companion, shedding light on the intricacies of the models and guiding me through the maze of available options.
Among the various parameters available, these were the ones I decided to focus on through lots of nudging from GPT:
- Learning rate: This parameter determines the contribution of each tree to the final prediction. A lower learning rate leads to more conservative updates and may require more trees to achieve optimal performance, but it can help prevent overfitting.
- Number of trees: The number of trees in the ensemble directly impacts model complexity and predictive power. A higher number of trees can lead to better performance but may also increase computational overhead.
- Maximum depth: The maximum depth of each tree controls its complexity and ability to capture intricate patterns in the data. Limiting the maximum depth can help prevent overfitting and improve generalization to unseen data.
Before diving into model building, it is imperative to process the data to ensure its quality and suitability for analysis. This involves handling missing values, transforming features, detecting outliers, and aggregating data as needed. By investing time in data preprocessing, we set the stage for effective modeling and ensure that our predictive insights are built on a solid foundation of clean, well-prepared data.
Building a Boosted Tree Regression model
Now,let us craft our boosted tree regression model using the CREATE MODEL statement in BQML. This statement lets us specify the model type, features, target variable, and relevant parameters. The following code snippet creates a machine learning model in BigQuery to predict costs based on project details, service type, and usage date to learn from historical billing data and make accurate cost estimations.
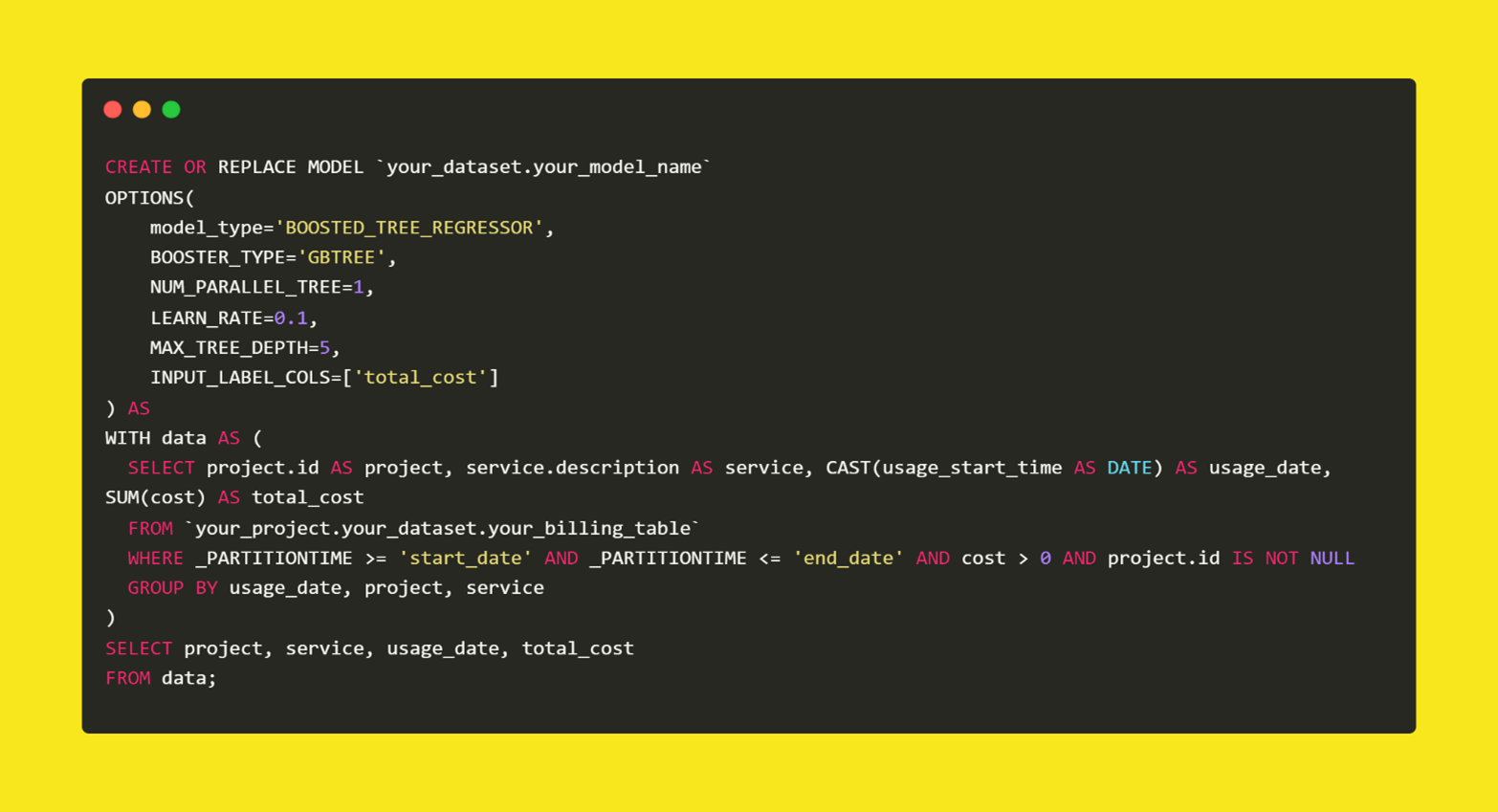
Figure 1: Creating a BigQuery ML Model
Once our boosted tree regression model is built, we gain access to a wealth of performance metrics automatically generated by the platform. These metrics include the Mean Absolute Error (MAE), Mean Squared Error (MSE), Mean Squared Log Error (MSLE), Median Absolute Error (MedAE), and R-squared (R²), among others. This streamlined approach to performance evaluation empowers us to iterate on our model, fine-tune hyperparameters, and optimize its predictive capabilities with ease, ultimately driving better decision-making and resource allocation strategies.

Figure 2: Forecasting Costs Using a Trained Model
Moving to the next step, we utilize the ML.PREDICT function to generate actual predictions from our model. This function seamlessly integrates into our workflow, producing output matching the input table’s structure. It includes all columns from the input table and additional columns for the model’s predictions. For regression models like ours, these columns are labeled as predicted_total_cost. With this setup, we can efficiently obtain forecasts for total costs, facilitating informed decision-making based on the predictive insights derived from our model.
The future of data-driven innovation
Utilizing Looker Studio, we transform our model predictions into actionable visualizations. These visual representations clearly understand forecasted costs, facilitating informed decision-making. This integration of BQML enables us to harness predictive insights effectively, as shown below.
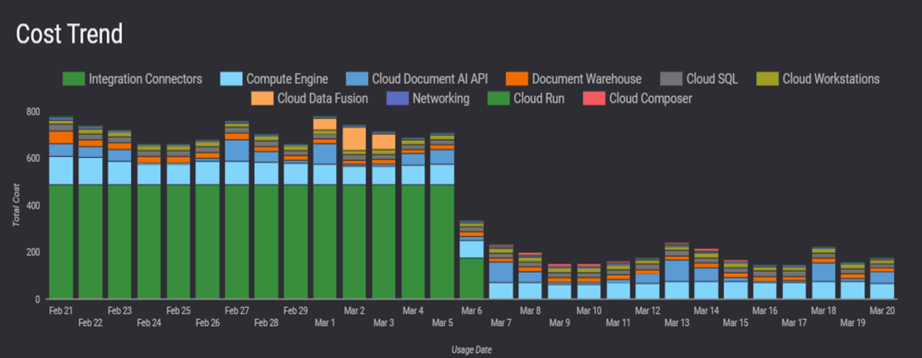
Figure 3: Visualizing Forecasted Costs with Looker Studio
Conclusion
As we conclude our exploration of BigQuery ML and its transformative potential for data engineers, it is evident that we’ve only scratched the surface of its capabilities. Through our journey, we’ve witnessed how this powerful tool can democratize machine learning, empowering individuals with diverse backgrounds to unlock insights and drive innovation.
Looking ahead, the horizon is brimming with possibilities. With each query and model built, we pave the way for smarter decision-making, more efficient resource allocation, and a deeper understanding of our data ecosystem. As data engineers, we stand at the forefront of this revolution, armed with the tools and knowledge to shape the future of analytics.
So, let us embrace this journey with curiosity and determination, leveraging BigQuery ML to unravel the mysteries hidden within our data and charting new paths towards data-driven excellence. Together, let’s continue to push the boundaries of what’s possible and unlock the full potential of our data-driven world. With BigQuery ML by our side, the adventure is just beginning.
Blogger's Profile

Vishnuvardhan Paramban
Senior Data Engineer-Data&Analytics
Vishnuvardhan Paramban is a Senior Data Engineer at LTIMindtree, specializing in building accelerators for modern cloud warehouse migration. With his expertise in cloud-based data solutions, particularly within Google Cloud Platform, he helps organizations transition to efficient and scalable data storage.
Latest Blogs
Core banking platforms like Temenos Transact, FIS® Systematics, Fiserv DNA, Thought Machine,…
We are at a turning point for healthcare. The complexity of healthcare systems, strict regulations,…
Clinical trials evaluate the efficacy and safety of a new drug before it comes into the market.…
Introduction In the upstream oil and gas industry, drilling each well is a high-cost, high-risk…
