


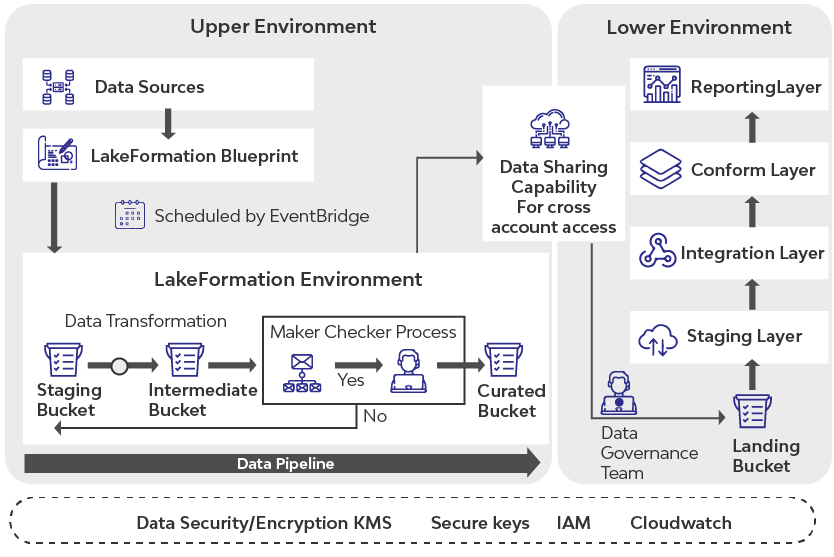
Guidelines for Cross-Account Sharing with Built-in Data Governance
A common use case in sharing data across multiple sub-organizations is refreshing the enterprise data warehouse through incremental data flow from the Online Transaction Processing (OLTP) applications. With many applications owned by various business units and with data access controlled through a process of governance due to the presence of sensitive data, the process of sharing and operationalizing the data movement becomes an involved task, as it must encompass data governance, data security, and audit.
Building on the current process that is a manual-intensive process not only increases in time but also loses its agility as the lag between the transactional applications and the analytical downstream increases. The downside to this is that the business making decisions using the analytical data that lags are not so accurate and well informed. For example, a typical underwriter in an insurance group is not able to decide after weighing all the risks and applying the policies to the latest data about the borrower. The lengthy process also adds direct, measurable costs through manual validation and audit, together with out-of-date architectures that drive up cost.
In this blog, we introduce a modern way of data transfer using AWS Step functions for orchestration, LakeFormation for Data Storage, EMR Serverless for data processing, and share the transformed data across another account. The automated process introduces a manual check that notifies a user, typically a data governance persona, by way of email and waiting for a response before deciding on the next course of action. On receipt of a signal post the manual activity, the process resumes, and it is left to the point of completion. A typical conversion process in this context involves desensitizing data as a result of data masking actions.
To illustrate the process, we break it into three steps. In the first step, we regularly sync the data from the OLTP database to an S3 bucket (Raw) using AWS Lake Formation Blueprint. Then, in step 2, we do data transformation based on the config file; this process also involves manual approval. As a last step 3, post the approval, we copy the approved data set to the curated bucket and enable the data sharing with another account.
Step 1:
For this illustration, we have two databases based upon Amazon Postgres RDS and Amazon MySQL RDS, synching the live data to a raw S3 bucket.
A logical architecture diagram is included below:
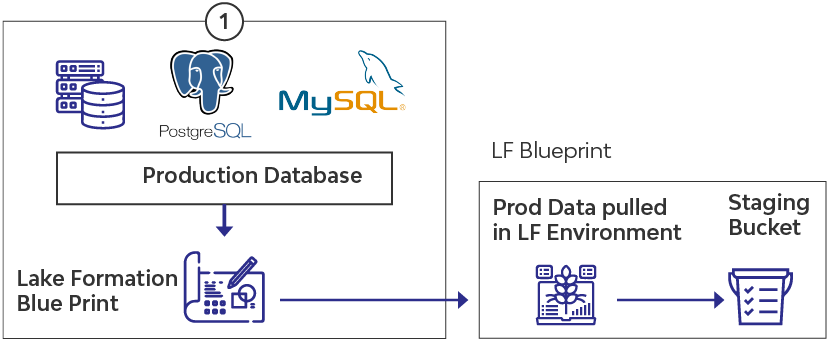
Data in the transaction systems is copied to the S3 bucket in the same structure as in production tables. We will use the AWS Lake formation blueprint service to perform the activity.
Each workflow creates and updates the data in S3 raw folder in the same structure as in the original OLTP Database. The databases, schema, and tables are organized hierarchically in the S3 folder with one folder per table and data files inside respective folders.
Data in the OLTP databases is continuously replicated into the AWS Lake Formation using AWS Lake Formation Blueprint. The replicated data resides in S3 and will contain all table data from all sources. The metadata is updated in Glue Catalog using APIs that create external tables as part of the EMR process.
Step 2:
In this step, we perform data transformation using a custom process that will remove the sensitivity of the data. The input to this process will be a config file, which defines the actions such as encryption, masking, bucketing, scrambling, and pseudonymization for many columns.
A logical architecture diagram is included below.
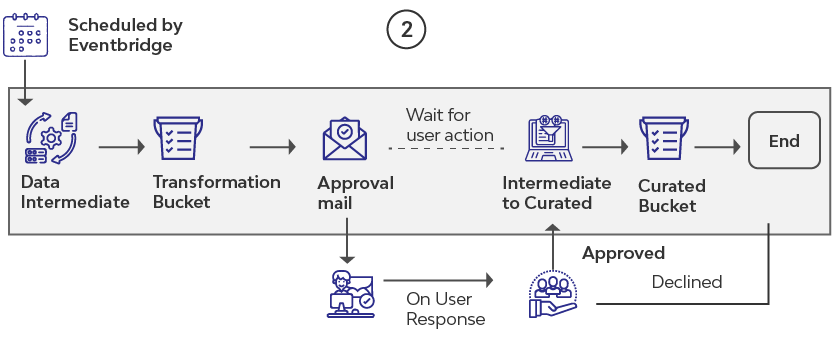
The process is orchestrated by an AWS Step Function and executed at configured intervals by an AWS Cloud Watch Event Bridge.
The following will be passed as parameters to the Step Function:
- Python script
- Location of the S3 bucket (Raw)
- Config file
Upon execution, the Python script will perform the transformation and write the output to a new bucket folder named “Intermediate,” and send an email notification to a designated person (QC).
The step function will pause in the next step, a “manual” activity, until it receives a signal.
The QC person, who is notified, can use Amazon Athena to perform validations on the data in the intermediate bucket. Each table in AWS Glue Catalog will be a consolidation of data across the two buckets: Curated and Intermediate. Together, the data will represent the production data in OLTP systems.
The transformation process will also update the external table definitions with the new partition of the data added to the intermediate bucket for each table.
Post the validation, the email-notified user can click the “Approve” button in the email to initiate an HTTPS request to the AWS API gateway, which post validating the secure token included in the URL call, will pass a signal to the manual activity step to cause the AWS Step Function to resume. As a next step, serverless data processing powered by EMR will copy the data from the intermediate bucket to the curated bucket. The step function process is said to have completed its execution.
Step 3
We demonstrate the ability to share data from the curated bucket in account “A” (Sharing account) to account “B” (Shared account).
A policy is created that grants cross-account access to the Lake formation data to another account. This policy grants access to another account and the root.
The admin user in the destination account creates the policy to grant the necessary role access to the data share.
Managing Permissions through LF Console:
After we create an IAM policy and grant access to a Cross-Account Admin, the admin can access the shared data and grant permission to IAM users/roles within his account through the Lake Formation console from his account.
Conclusion
In this blog, we created an AWS Lake Formation to regularly sync data from the OLTP database into the S3 bucket. We created an AWS Step Function to process data with a manual approval process. We also demonstrated Data sharing across accounts with permissions at a granular level. For data processing, we used AWS EMR serverless for data processing, AWS IAM for access restrictions, and AWS KMS for data encryption at rest.
If you have any questions or suggestions, please feel free to reach out to us at lti_data_aws@ltimindtree.com
Blogger's Profile

Rajan Seshadri
Principal - Data Engineering, LTIMindtree
Rajan Seshadri is a recognized digital thought leader with 25+ years of extensive experience in Strategic Consulting and Solution Architecting for Data Modernization, Data Engineering, AI/ML, Cognitive Analytics –Visualization/Story Telling. At LTIMindtree, he heads the AWS COE for Data and Analytics and is known for his passion for driving innovation, digital transformation strategies, maximizing operational excellence, and delivering financial performances and business outcomes to customers. He has certifications in AWS Solution Architect Professional and AWS Database Specialty.
Latest Blogs
Introduction What if training powerful AI models didn’t have to be slow, expensive, or data-hungry?…
Pharmaceutical marketing has evolved significantly with digital platforms, but strict regulations…
Leveraging the right cloud technology with appropriate strategies can lead to significant cost…
Introduction The financial industry drives the global economy, but its exposure to risks has…
