


Embracing the Future with Generative AI Operationalizing Large Language Models using Snowflake and AWS SageMaker
Introduction to AI and the rise of Generative AI
The journey of artificial intelligence started in the 1950s when Alan Turing tried to determine if a machine could mimic human intelligence. Since then, AI has come a long way and has seen many phases. While earlier AI systems were focused on rule-based reasoning and expert systems, in the second phase (1980–2000), the focus shifted towards data-driven approaches and machine learning. In the third phase (2000–2020), the growth of AI was driven by big data and the cloud, with research expanding to areas like Natural Language Processing, Computer Vision, and Conversational AI.
The advent of AI has resulted in the development of niche deep learning models and techniques, along with the emergence of large-scale neural network models. Over the years, developers have built a few models leveraging large-scale neural network types like Generative Adversarial Networks (GAN), Generative Pre-trained Transformer (GPT) models, and Large Language Models (LLMs).
These models, trained on billions of parameters, show better natural language understanding and generation capabilities. The latest iteration of models from OpenAI, Microsoft, Google, AWS, and other open-source models from Hugging Face are pushing the boundaries of AI even further.
Overview of Generative AI and LLMs
Generative AI refers to a category of machine learning algorithms that generate new data like the original input data. Essentially, these algorithms create something new that mirrors the properties of the given input. These models excel at creating realistic and high-quality data in text, image, audio, or video formats.
The key types of Generative AI models include Generative Adversarial Networks (GANs), Variational Autoencoders (VAE), transformer-based models like the GPT series, and Hugging Face models. The GANs contain two neural networks: the Generator network that generates data and the Discriminator network that distinguishes the generated data from real data. The VAEs use neural networks to encode the data into lower dimensional space and then decode it back, enabling efficient data generation. The transformer models like GPT-3.5, GPT-4, etc., primarily focus on text-based data, using the self-attention mechanism to generate meaningful text using the provided input text data.
These text-based models are referred to as Large Language Models (LLMs). These LLMs are typically designed with a large number of parameters and trained on vast amounts of data. For instance, the current generation of the GPT-3 model is built on 570GB of text-based data. It leverages over 175 billion parameters for training the model. These LLMs can be fine-tuned for specific tasks like text generation, summarization, translation, question answering, etc.
Why enterprises need LLMOps
While the Generative AI foundational models are powerful, organizations require to finetune and manage these models effectively to reap the benefits of these models. The key is to help manage the operational capabilities and infrastructure requirements to help fine-tune the existing foundational models and deploy these refined models. The overall value chain of managing and operationalizing these models comes under Large Language Model Operations (LLMOps). It is a subcategory of ModelOps/MLOps and deals with the LLM’s life cycle management, including fine-tuning, deployment, evaluation, monitoring, and maintenance.
The LLMOps landscape includes platforms, frameworks, and support tool chain. Platforms are where you can fine-tune, version, maintain prompts, and deploy the models. These platforms provide the necessary infrastructure and automation support, leveraging frameworks such as LangChain, DUST, etc. This helps AI engineers to build custom LLM-based models and applications quickly. The support tool chain helps to streamline workflows, such as testing prompts (e.g., Promptfoo) and incorporating human feedback.
Operationalizing LLMs with Snowflake and AWS SageMaker
With the rapid advancements in AI, there is a growing need to operationalize LLMs in various applications. Popular open-source AI communities and other well-known organizations are playing a crucial role by contributing to the open-source LLMs like BERT by Google, RoBERTa and LLAMA by Meta AI, GPT by OpenAI Labs, along with a vast transformers library provided by Hugging Face and many more.
We can take these open-source, pre-trained LLMs and fine-tune them to align with the specific business requirements. However, operationalizing these LLMs with cross-platform integration can be quite challenging. One such approach could be taking a pre-trained Hugging Face model, fine-tuning, training, and deploying the model on AWS SageMaker. The next step would be inferencing the model with the data stored in the warehousing platforms like Snowflake. Visualizing the data insights can be done using solutions like Streamlit. Let us go through the steps as a part of this approach.
Genai snowflake
Figure 1 Key Lever for LLMOps on Snowflake
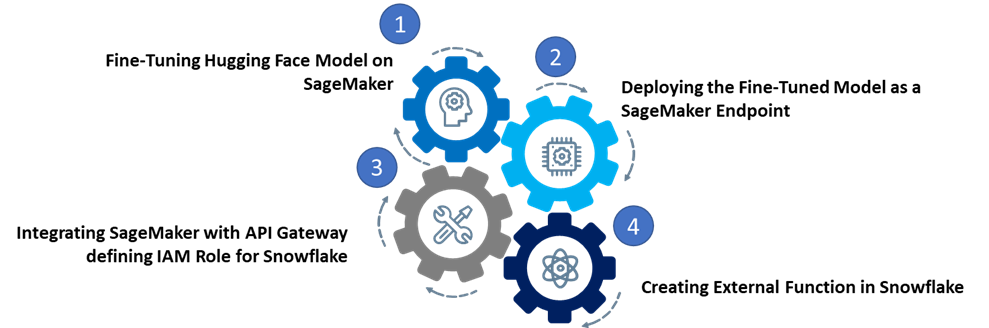
Step 1 – Fine-tuning Hugging Face model on SageMaker
First, we select an appropriate foundation model for the business need. Hugging Face offers multiple foundation models to choose from. Using SageMaker’s Hugging Face Deep Learning Containers, we can easily run the training and hyperparameter tuning jobs with the pre-trained models from the Hugging Face Hub.
Once the model is finalized, we initialize the SageMaker Hugging Face estimator with the selected model. Here, we also define the number and type of instances needed for model training, the Hugging Face model version, and the hyperparameters required in the tuning job. We also provide the path to the S3 bucket where the training data is stored.
We also provide the training script as an entry point, where we define the steps for fine-tuning, load the dataset, and specify our training parameters. Once done, we call the fit method, which initiates the SageMaker training Job.
Step 2 – Deploying the fine-tuned model as a SageMaker endpoint
The next step is to deploy the fine-tuned model to a SageMaker Endpoint. This SageMaker Endpoint will be used to perform the inference. Here, we will first create a model in SageMaker by pointing to the S3 location where the fine-tuned model artifact is stored. Then we will input the model deployment configurations, such as instance type, instance count, etc. Finally, we will deploy the model to an endpoint for real-time inference.
Step 3 – Integrating SageMaker with API Gateway defining the IAM role for Snowflake
Once the endpoint is deployed to SageMaker, we set up the API Gateway, which acts as a front door to redirect relevant API requests to the SageMaker Endpoint. Here, we also utilize the capabilities of the AWS Lambda function for handling the requests and responses to and from the SageMaker Endpoint. This Lambda function is also used to perform crucial tasks like Prompt Engineering and format the input data.
At this point, we also define the Identity and Access Management (IAM) role and policy for allowing the API gateway authorization from our Snowflake account. This acts as a security firewall to safeguard our communication between the AWS API Gateway and Snowflake services.
Step 4: Creating an external function in Snowflake
External Functions in Snowflake are used to call external APIs, like our API Gateway REST Endpoints, through SQL queries from within Snowflake. To achieve this, we will first create an API integration object in Snowflake to interact with API Gateway. Next, we set up an External Function in Snowflake that calls the API Gateway endpoint. Finally, we use this External Function in our SQL statements to infer our model hosted in SageMaker.
The data processing workflows in Snowflake can directly leverage the machine learning capabilities from SageMaker with this setup. This enhances our data visualization and explanations using visualization tools like the Streamlit application.
Conclusion
The AI story is becoming important with the rise of LLM as a key pillar for Generative AI. The pivot remains moving towards operationalizing the early-stage proof of concepts (PoC) or minimum lovable products (MLP) into a full-fledged production environment. As the intricacies around the models rise, the emphasis on ensuring the solutions remains the key element for AI-driven growth. LLMOps place a centrifugal force to ensure the operationalization of the LLM use cases at scale. The model, once trained, is well-evaluated and monitored to ensure optimum results for the customers, leveraging the power of Snowflake and AWS SageMaker. Operationalizing LLMOps helps understand LLM behavior and evaluate the critical elements like right-sizing model infrastructure, ensuring optimum model performance, and monitoring. This will help businesses embark on a true digital journey by managing the power of cloud computing with smarter, responsible, and scalable AI insights powered by Generative AI.
Blogger's Profile

Ronak Kataria
Data Scientist, AI & Data Engineering, Data & Analytics Practice, LTIMindtree
Ronak is a seasoned Data Scientist and MLOps Architect with over five years of experience in the field. His expertise lies in designing and implementing scalable machine learning solutions, leveraging data-driven insights, and orchestrating ML workflows and operations to optimize business processes.
Latest Blogs
A closer look at Kimi K2 Thinking, an open agentic model that pushes autonomy, security, and…
We live in an era where data drives every strategic shift, fuels every decision, and informs…
The Evolution of Third-Party Risk: When Trust Meets Technology Not long ago, third-party risk…
Today, media and entertainment are changing quickly. The combination of artificial intelligence,…
