


DataOps as a Service: Transforming Your Business
About DataOps
The DataOps platform is a transformational shift from traditional DevOps that aims to enhance communication, integration, and automation of data flow between data providers and consumers.
From a 10000-feet view, one could see DataOps as a collection of best practices, processes, and architectural patterns to follow while building any data use case. The process includes data collection, aggregation, enrichment, transformation, collaboration, and enabling the data for business use cases. At the same time, governance and security are commonly known as end-to-end data pipelines without cutting corners on deployment.

The Necessity for DataOps Platform
As per Gartner, organizations need to change the way they work to relieve bottlenecks and barriers in the delivery of data and analytics solutions. Data and analytics executives can influence a move towards quick, flexible, and reliable delivery of data pipelines by implementing DataOps methodologies in a focused manner.
Enterprises moving from on-premises data architectures to solutions in the cloud often find that they don’t realize the benefits they hoped for. Six years ago, McKinsey estimated that only 1 percent of most data created and captured had been analyzed.
With the rapid cloud transformation and high-growth rate of data, we observe challenges in complex transitions, increasing management overhead because of the complex web of technologies for data management in the cloud. As a result, despite pouring billions, large volumes of redundant data are left unanalyzed.
Current and future trends
DataOps as a service is now becoming a compelling necessity to manage data drift by ensuring continuous data flows through automation. It aims to operationalize the data management life cycle into a continuous and reliable data flow to the end user with business insights and value.
Further, the below trends are being observed in the DataOps ecosystem:
- Internet of Things (IoT)
- Adoption of Open-Source tools
- Automation
- New roles in the software ecosystem
To meet this growing trend, what’s needed is an end-to-end cloud data platform and a self-serve DataOps tool. Once set together, it will provide an enterprise-class DataOps platform. This powerful combination caters to regional and global enterprise data needs, helping to unify and streamline the operational reporting, self-services, data analytics, and data science capabilities of hyper-distributed data.
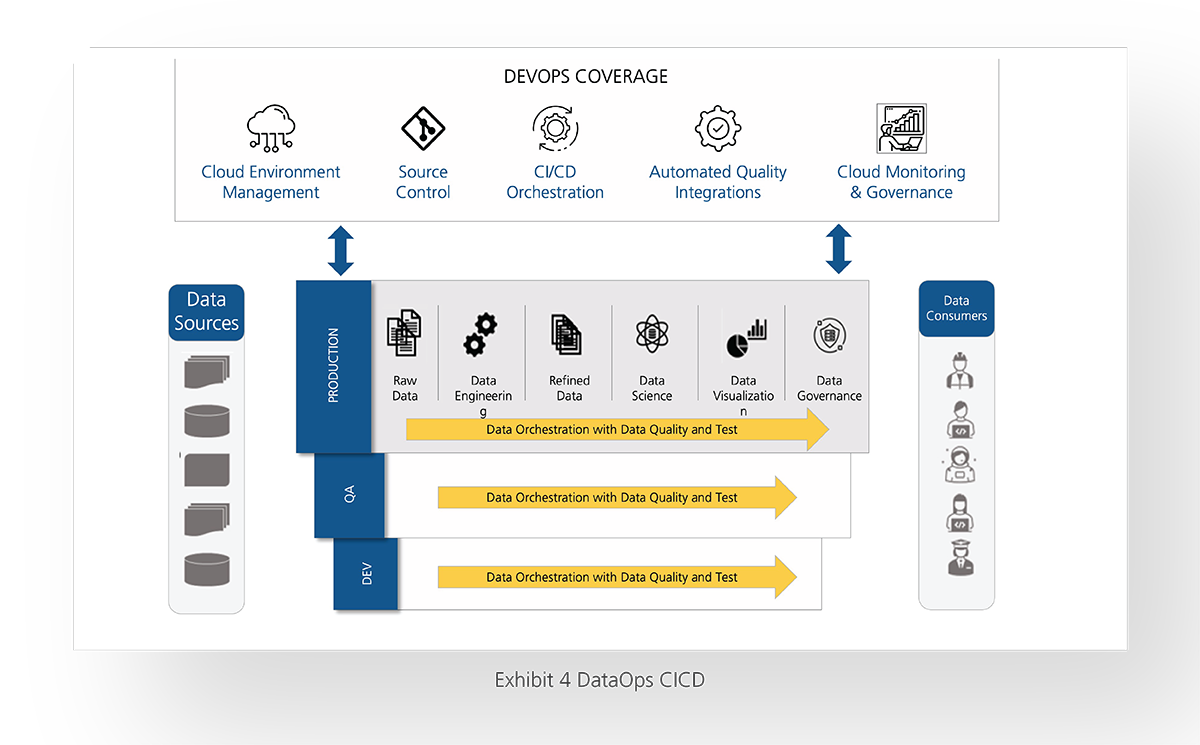
End-to-end DataOps
As a data-driven organization, data stewards and product owners (on the left side of the infinity in Exhibit 1) define the business plans. Data engineers help in the implementation by sourcing the data, transforming, enriching, and storing the data to cater to diverse needs. While data analysts and data scientists (on the right side of the infinity in Exhibit 1) can consume, test, and train models, visualize, and make them available for downstream systems or enable self-discovery.

Exhibit 1 shows the set of architectural principles, processes, tools, and personas. The below section will help to understand the data pipeline, continuous integration, and continuous delivery of the data pipeline.
A data pipeline is a process in which data is ingested from various data sources, stored, processed, transformed, and published for others to consume. In batch processing, data loads in batches with a set time of intervals, while in streaming, data is continually updated.
The data pipeline has three phases, as represented in Exhibit 2. It also represents the common tools used across the phases.
Data sources and data ingestion: Data is collected from various data sources, which include various data structures (i.e., structured and unstructured data).
Data transformation: Process data into the format required by the destination data repository. A well-defined automation process ensures that data is cleansed and transformed consistently and delivers high-quality data for data consumers.
Data analysis: The transformed data is then stored within a data repository, where it can be analyzed and exposed to various consumers.
Data delivery: The proceeding data is consumed and transformed into visual content for identifying patterns, data points, and trends.
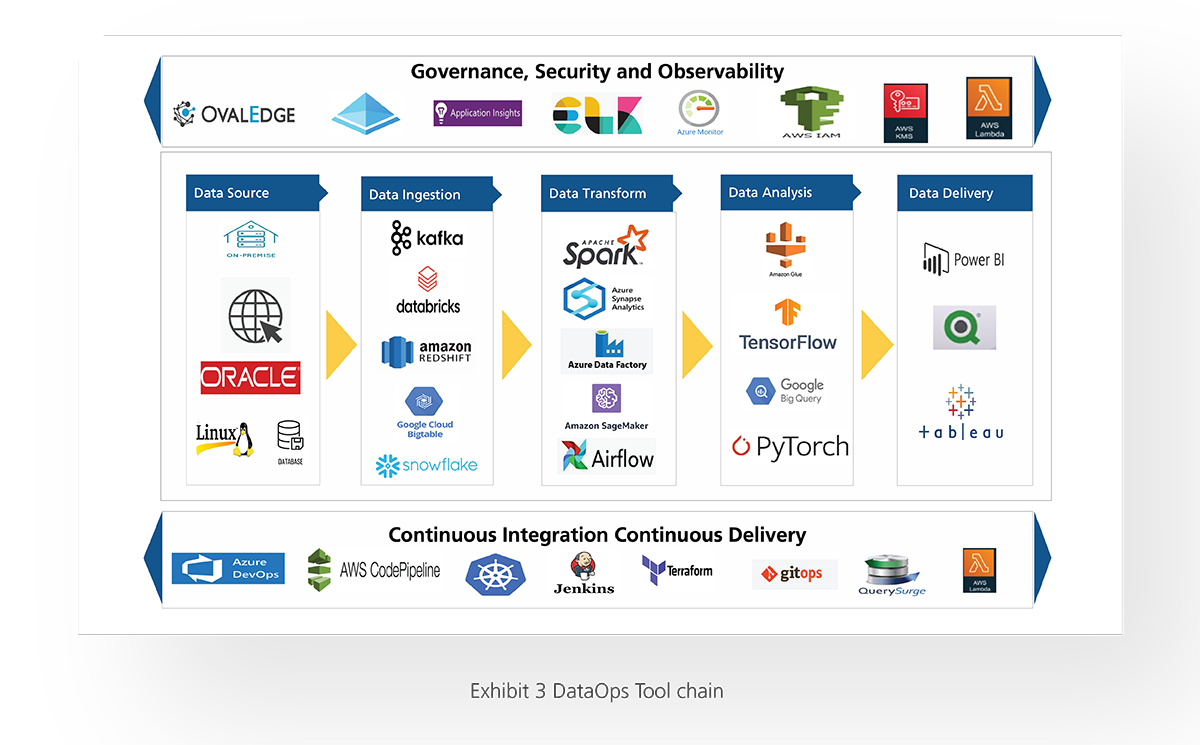
Along with the data pipeline, continuous integration and delivery are key for agility and consistency. Leverage infrastructure as code and containerization, integration of fully Git-based development flow, automated testing at every stage, publish when you know data is good, end-to-end logging and monitoring, governance, and security enforcement across components.
DataOps KPIs
Several measurements can be considered in DataOps. Below are some of the key metrics.
- Data processing time
- Efficiency of design effort
- Number of failures
- Number of issues reported for data quality
- Number of custom policies implemented
- Effective utilization of cloud services
DataOps Benefits
- Promotes a better understanding of data and what it represents
- Increases IT project velocity through data automation
- Reduces fragility through standardization and repeatability of data tasks
- Enhances testing through “production-like” data and patterns
- Ensures PII compliance with industry regulations, e.g., GDPR
- Ensures enterprise (as well as customer) data and risks are secure
- Ensures “quality data” that support AI/Machine Learning
- Enhances “data” collaboration within the DevOps teams
As the demand for DataOps is growing, it is also important that businesses monetize data at speed and scale by providing best-in-class capabilities. A comprehensive DataOps solution is needed to meet the requirements across the data lifecycle offering the KPIs and benefits powered by the cloud. The Fosfor suite of products has an extensive set of go-to-market and technology partnerships with leading cloud companies. It has been recognized by leading industry analysts.
Fosfor-Spectra
LTIMindtree’s “Fosfor -Spectra” is a comprehensive cloud-native DataOps platform that helps data engineers and data analysts transform data assets by:
- Enabling decentralized, domain-oriented teams to build data pipelines and data products independently
- Allowing connections to many diverse sources of data without complex programming
- Extracting insights from all types of data, including structured, semi-structured,
and unstructured data - Accommodating variable data lifecycles from creation, through usage, to eventual archive and deletion
- Allowing for the centralization and governance of data in the cloud while still supporting decentralized DataOps
For organizations using the Snowflake platform, Fosfor Spectra is particularly well suited to support a scalable, high-performing cloud-based ecosystem, seamlessly connecting to data from various systems and applications. Fosfor Spectra streamlines the building of data products by providing a self-serve, no-code platform leveraging the advanced capabilities of Snowflake, including the Snowpark developer experience.
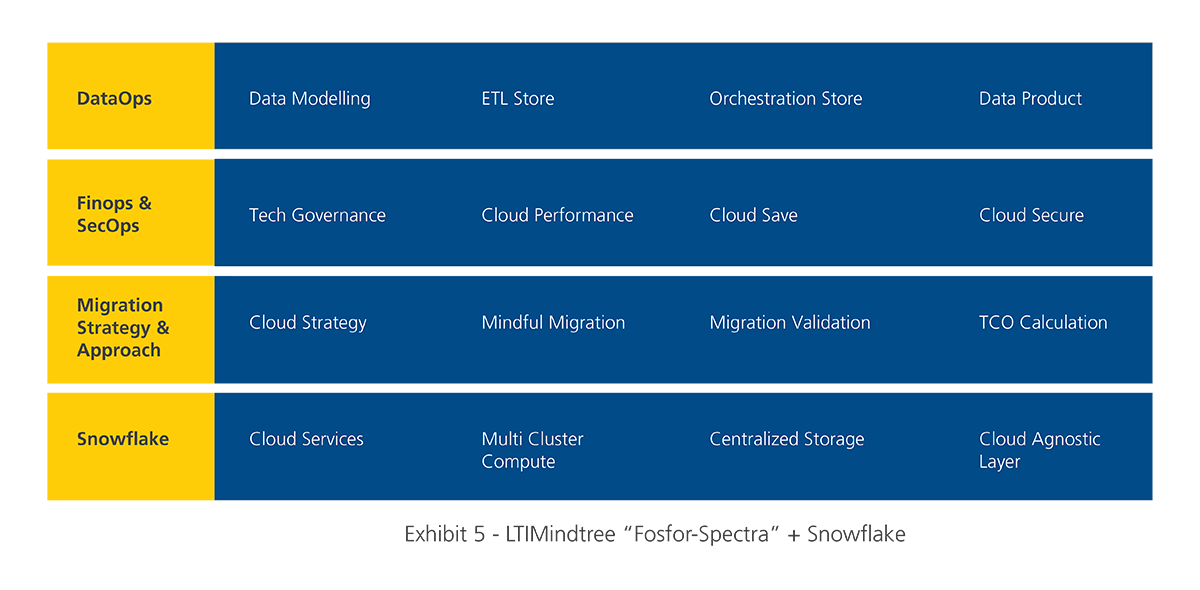
With the above features, we could decentralize and democratize the data pipelines to cater to diverse business domain needs and support data products without compromising governance, security, and scalability for storage and computing.
Use Case
A leading global battery manufacturer required a modern data and analytics platform to speed up data engineering and bring advanced analytics capabilities. However, it wanted the platform to be simple to use, giving more people across the organization data access to drive more business value.
The challenge was to build a scalable and high-performance cloud-based platform connecting to data from various systems across various applications. Leveraging “Fosfor Spectra” and Snowflake’s combined capabilities, LTIMindtree helped this customer shift from a siloed application architecture to an integrated, user-experience–driven architecture.

Conclusion
DataOps simplifies the complexity of data collection, data processing, data analytics, and operations. Successful implementation of DataOps requires defining a set of practices. Every aspect must be considered from a coder’s mindset to improve agility, integrated quality with gates, automated testing, and continuous delivery of production-ready data and operations-ready analytics.
Blogger's Profile

Adil Pathan
DevOps Architect, Cloud Practice, LTIMindtree
He has 14+ years of IT experience in multi-Cloud technologies. Transforming enterprise customers to DevOps adaptations, leveraging experience and DevOps best practices. He likes sports and traveling.

Rohan Bhosle
DevSecOps Architect, Cloud Practice, LTIMindtree
He has 16+ years of IT experience with a rich background in implementing DevSecOps solutions for multiple application technologies and cloud platforms. He has experience in DevSecOps transformation via consulting and architecting assignments around Cloud/DevSecOps for enterprise customers. He likes traveling, trekking, and music.
Latest Blogs
Core banking platforms like Temenos Transact, FIS® Systematics, Fiserv DNA, Thought Machine,…
We are at a turning point for healthcare. The complexity of healthcare systems, strict regulations,…
Clinical trials evaluate the efficacy and safety of a new drug before it comes into the market.…
Introduction In the upstream oil and gas industry, drilling each well is a high-cost, high-risk…
