


Can NLP’s New-Found Power Turbo-Charge Software Delivery?
Sir Isaac Newton wisely once said, “If I have seen further, it is by standing on the shoulders of giants.”
The richness of the human language to communicate, store new knowledge distinguishes humans from other inhabitants of this blue planet. Language opens a world of possibilities, from completing the mundane task of filing a life insurance form, enjoying the rich literature of the classics, tackling bafflingly complex calculus that unerringly puts satellites into orbit, and much more.
Getting machines to learn our language or natural language processing (NLP) has been the proverbial El Dorado in Silicon Valley and other tech corridors.
What exactly is Natural Language Processing?
Natural language processing (NLP) is the ability of a computer program to comprehend human language as it is spoken and written. Natural language processing in AI is an area that allows computers to comprehend natural language in the same way that humans do. Natural language processing, whether spoken or written, uses artificial intelligence to take real-world input, process it, and make sense of it in a way that a computer can comprehend.
What are Large Language Models (LLMs) or Foundation Models (FM)?
Pioneering research in NLP in word embeddings – Word2Vec, the recent arrival of Transformer models—BERT by Google, GPT3 by OpenGL—and continuous growth in these pretrained large language models (LLMs) are enabling machines to understand human language with remarkable accuracy in a big way.
The now seminal paper Attention is all you need by Google researchers Ashish Vaswani, Noam Shazeer et al. unleased the Transformer model along with its vast new possibilities in Natural Language Processing.
Like an arms race, all these Transformer-based models and variants essentially continue to grow humongous in size—from Google’s BERT 340 million parameters to Open AI’s GPT3 with 175 billion parameters to the recent LLMs of Microsoft NVIDIA MT-NLG 530 billion and Google PaLM 540 billion parameters—all within is a short span, which is quite significant. Each model improves the performance of its language tasks over the previous one.
Pretrained on billions of tokens (words) under the steady compute crunching of a battery of high-end GPU servers, these Large Language Models can perform a large set of tasks. These tasks are generally such as text summarization, sentiment analysis, sentence similarity, named entity recognition, language translation, speech-to-text, text generation, and much more in a big way. All this with reasonably accurate predictions with only a handful of data labeling.
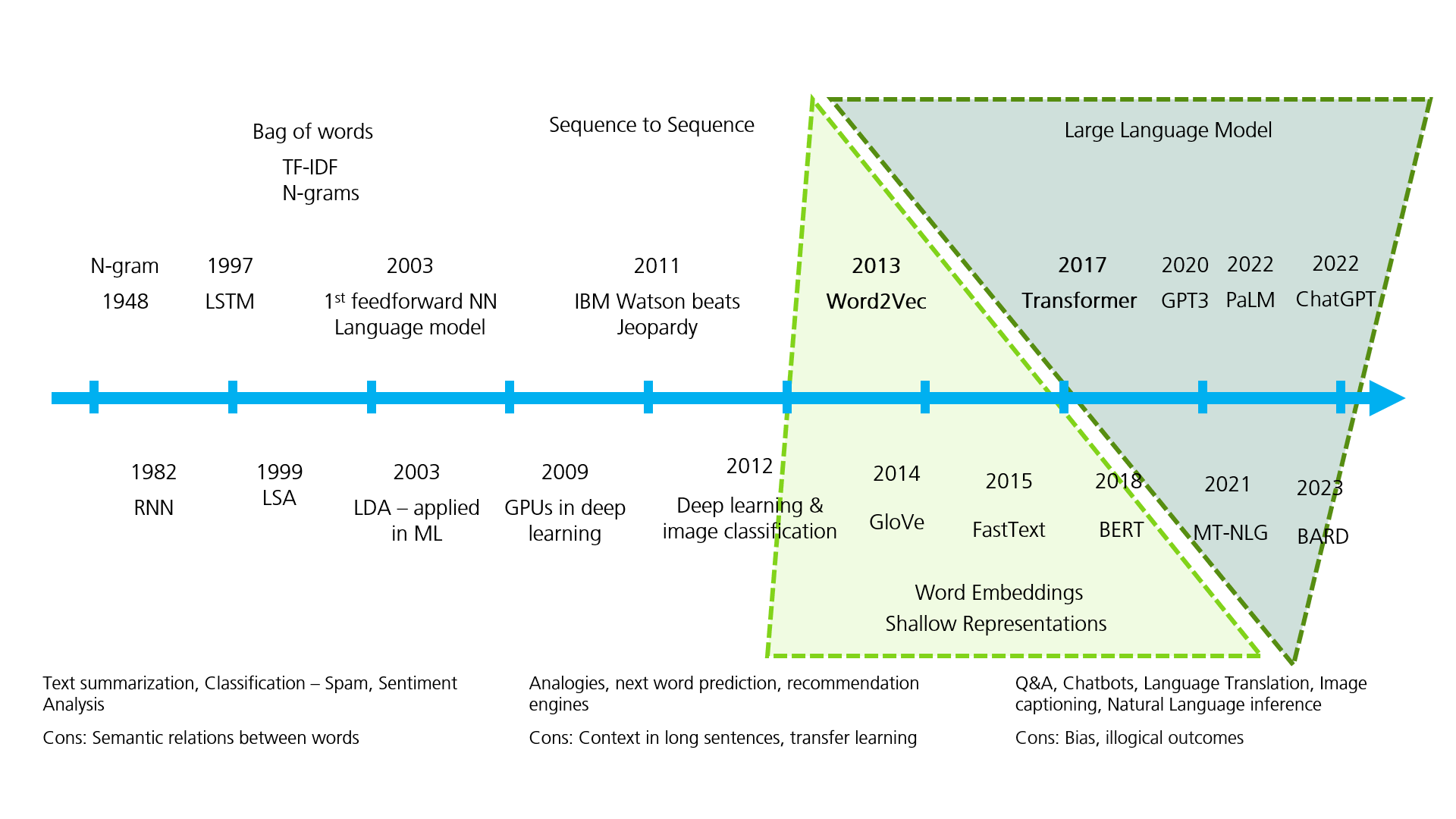
Fig 1: Evolution of NLP Techniques
Image Source: Author, Adish Apte
What this means explicitly is that these LLMs can correctly answer complex medical queries and explain a biological root cause. It can generally write a “self-introspecting” article about it being a robot and earnestly argue to dispel the apprehensions of modern-day Cassandras calling out AI as the beginning of the end of humankind.
Without a doubt, we are at an inflection point of leveraging the new raw power of NLP, with a gamut of use cases being nudged ahead by the band of newly minted unicorns. The use case I explore here is as below.
Use case: NLP to drive software delivery productivity
The SDLC, or software development life cycle, produces a variety of data. This includes user experiences, test cases, defects, log files, code files, audio files (product grooming) – most of which are unstructured in English—and semi-structured data. All this data is presently going to waste, providing no insights for software delivery personas. The big question is whether we can use these new natural language processing techniques to extract insights from this data to assist different software delivery personas in making smarter and faster delivery decisions.
Before we look at these smarter use cases for all purposes, let us consider a sample large IT program. Consider a program with 20 scrum teams with ~10 user stories per sprint with over two years to deliver ~8000 user stories. By the time you develop the test cases, capture the defects, and code with comments – you end up with a lot of useful unstructured data.
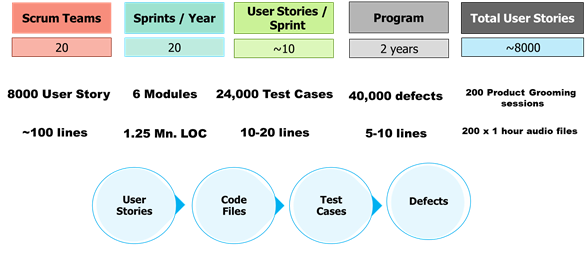
Fig 2: The rich unstructured data collated in any large Enterprise IT program.
Image Source: Author, Adish Apte
Volume, velocity, and variety of data are the staple diet for Artificial Intelligence (AI).
Now, are you leveraging this data pile for any practical purpose? Can you leverage any of this data to derive any valuable insights essentially? This is where the power of Natural language processing in ai subtly comes into play.
The very superior performance of new-age Natural language processing algorithms at sentence similarity, entailment, reading comprehension with common sense reasoning, and choice of possible alternatives specifically give rise to a host of use cases for solving hitherto unsolvable or undiscovered software development life cycle (SDLC) problems.
Select use cases of “smarter and faster” software delivery
If you essentially have developed, say, an insurance product for motor fleets on the East Coast in the US, and a different team at a different point in time kind of is developing a similar product for the West Coast or, say, in Europe for the same global insurer, will the teams be aware that something primarily similar has been already developed in a big way?
The sentence similarity will help to kind of arrive at similar-looking use cases from the entire organizational knowledge base. And will be contextually much closer than the natural language processing models hitherto allowed.
To extend the above use case: An architect is essentially trying to estimate the efforts for a new change request in an existing business-critical application, which is significant. Can she look at all the potentially impacted user stories and understand the web of correlations across the applications, user stories, test cases, defects, and code files, which is significant? Or is it possible to uncover any of the specific software modules have a high density of defects associated and then, for the most part, allocate more effort margins to compensate for any unforeseen additional work?
Developers generally loathe writing comments to code. Mostly without the comments, the technical debt grows. Natural language generation will specifically allow, for all intents and purposes, better code comments and a better understanding of code for other developers & assist in a major way. Also, it provides the searchability of code with specific functionality, enabling future reusability.
For example, if a software developer is trying to resolve a rather obstinate software issue and would like to have a much better understanding of the business terms. Apart from narrowing the search to the relevant business requirements document, she can apply commonsense reasoning to quiz the understanding of the business process.
These exciting use cases in the software delivery space are just the tip of the iceberg of possibilities, firmly proclaiming that Natural Language Processing or NLP is the idea whose time has come.
For more such insights please visit: Canvas by LTIMindtree.
Blogger's Profile

Adish Apte
Principal Director- Product Engineering, Canvas by LTIMindtree
Adish leads the Canvas Platform in LTIMindtree. With over 25 years of IT industry experience, Adish brings strong experience across product management, relationship management, and sales. Apart from leading the Canvas Platform development, he uses innovation of AI/ML, particularly NLP, knowledge graphs, and ontology, to deliver new insights and accelerate software delivery.
More from Adish Apte
While computers work well with structured data and well-defined algorithms, they are woefully…
Latest Blogs
Introduction What if training powerful AI models didn’t have to be slow, expensive, or data-hungry?…
Pharmaceutical marketing has evolved significantly with digital platforms, but strict regulations…
Leveraging the right cloud technology with appropriate strategies can lead to significant cost…
Introduction The financial industry drives the global economy, but its exposure to risks has…
