


A Cursory Glance at Large Action Models
AI has progressed from discriminative to generative, enabling better technology engagement, data forecasting, and interpretation. Now, the focus is shifting towards integrating and correlating various data classes, helping us better comprehend our external and internal environment. We are witnessing a revival in newer applications of natural language processing and computer vision, thanks to the emergence of powerful pre-trained Large Language (LLM) and Visual Language Models. LLMs are becoming proficient in interpreting intricate real-world language data, while some claim that it has the potential to surpass human intelligence.
In recent times, research into using multi-modal data in LLMs has unveiled new possibilities for stacking multiple artificial intelligence/machine learning models to create what is known as Large Action Models (LAM). In this digital era, where data converges from diverse streams, the fusion of different modalities—text, images, audio, or more—stands as defining criteria for LAM. In this blog, we will explore the exciting world of LAM in AI. We will delve into how different types of data interact and the endless possibilities at the intersection of AI and multi-modal data integration.
What are Large Action Models?
LAMs are derived from LLMs and serve as an extension of LLMs by transforming them into autonomous agents. These agents are software units that can execute tasks and make decisions without human intervention. Instead of simply responding to user queries, LAMs utilize the linguistic proficiency of LLMs to carry out tasks and decision-making processes independently.
The underlying principle of LAMs lies in the amalgamation of various applications and the corresponding human actions they aim to replicate. LAMs can effectively simulate the combination of different applications and the human actions performed on them, eliminating the necessity for temporary demonstrations or textual explanations.
According to OpenAI’s technical report, GPT-4V has demonstrated significant promise in understanding language and images in a real-world setting. Its sophisticated semantic analysis capabilities are found to break down human instructions into complex tasks for robots. Nevertheless, current multi-modal foundation models, including GPT-4V, continue encountering difficulties in achieving detailed manipulation that requires predicting actions.
Henceforth, a large action model that encompasses language proficiency, visual cognition, contextual memory, intuitive reasoning, and the ability to forecast adaptable actions is under consideration. This research aims to lay the groundwork for creating general AI models using multi-modal data gathered from various sources.
What are the key components of LAM?
Large action models for multi-modal generalist systems consist of five main modules: (1) modules for environment and perception with task planning and observation, (2) modules for learning, (3) memory modules, (4) action modules, and (5) cognition modules. Cohesive integration of these modules contributes to the development of artificial general intelligence. A notable feature of LAM is that the model’s actions, once trained, directly impact task planning without the requirement of receiving feedback from the environment for planning subsequent actions.
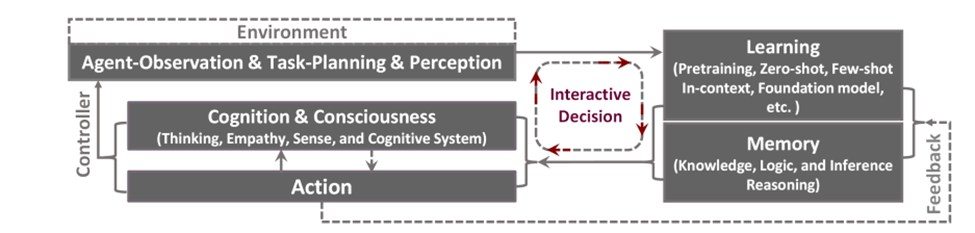
Fig.1: LAM Workflow, Position Paper: Agent AI Towards a Holistic Intelligence, Qiuyuan Huang, Naoki Wake, Bidipta Sarkar etl., arXiv: https://arxiv.org/pdf/2403.00833
- Learning: LAM models can adapt to novel environments through training and pre-training data, reinforcement learning (RL), or supervised learning from human demonstrations, such as imitation learning (IL) or behavior cloning. Once the model is trained, it can enhance its performance by observing its surroundings and understanding the consequences of its actions on the working environment.
- Memory: Long-term memory enables the LAM to retrieve operations that can be modified to suit the environment or user preferences. Conversely, short-term memory is associated with the actions taken and observations made during an operation. Short-term memory empowers the system to reassess and plan future actions based on past experiences.
- Action: LAM’s actions are contingent upon the environment in which it operates. These actions may involve interactions within virtual reality (VR) environments or verbal communication with humans. LAM selects an appropriate action by utilizing its cognitive processes and drawing from acquired skills and memory.
- Perception and planning: LAM necessitates multimodal perception to understand its surroundings effectively. Audiovisual perception is crucial for models to interpret human intentions through mediums like images, videos, and gameplay. In tasks such as object manipulation, planning plays a vital role. A goal-oriented planning approach offers LAM flexibility in dealing with uncertainties arising from external and internal factors.
- Cognition: LAM prioritizes the efficiency of its components and underscores the system’s overall utility. For example, when a novice user interacts with a new device or robot, the LAM model quickly adapts to perform tasks within the user’s environment. A mechanism is essential to facilitate the complex and coordinated operation among various components of LAM. This coordinating function is commonly referred to as the cognitive aspect of LAM.
Is this just another hype?
LAM in AI aims to develop an interactive system that communicates with humans and interacts with environments through its perceptual capabilities, employing actions aligning with human intents. LAMs will help transition AI models from working on passive, structured tasks to dynamic, interactive roles in complex environments. Further R&D in LLMs and VLMs will enable LAMs to parse and infer human intent from various domain information, actions, natural-language instructions, and multimodal contexts.
Despite its tremendous potential, LAM will face difficulties in generalized performance in unknown/untrained scenarios. However, LAMs can leverage the knowledge base of pre-trained/foundation models (ChatGPT, Dall-E, GPT-4, etc.) to create a foundational layer between the user and the model. Since LAMs can process and manage multi-modal data, they can gain pertinent information from micro-reactions from users in multi-modal environments, comprehend unseen scenes from explicit web sources, and deduce implicit knowledge from the results of pre-trained models. It can also make changes based on variations in target activity, language pattern, and user macro behavior.
As we journey through the exciting world of AI, the ongoing progress in LLMs and VLMs, as well as the ability to blend different data types, is crucial for unleashing the full potential of LAMs. With each step forward, we are getting closer to a future where AI works alongside us, understands detailed instructions, and adapts easily to different situations. This progress is not just about technology; it’s about how it can positively impact industries and people worldwide, moving us closer to artificial general intelligence. Additionally, LAM as a breakthrough in the field of AI, can empower organizations to navigate obstacles while being innovative, thus leading to more successful outcomes.
References
GPT-4 Technical Report, OpenAI: https://arxiv.org/pdf/2303.08774
Blogger's Profile

Bharat Trivedi
Principal Architect, GTO
With over 20 years of experience, Bharat is a product developer by heart. He has played a key role in introducing high tech in various sectors, including Retail Banking, Capital Markets, Online Trading, and the Regulatory Space. Bharat’s unique perspective on technology makes him an adept mentor for aspiring professionals.
More from Bharat Trivedi
Introduction Automation is a critical enabler of digital transformation for any organization,…
The answer to why Quantum Technology is unique and different from classical technology lies…
Latest Blogs
Introduction What if training powerful AI models didn’t have to be slow, expensive, or data-hungry?…
Pharmaceutical marketing has evolved significantly with digital platforms, but strict regulations…
Leveraging the right cloud technology with appropriate strategies can lead to significant cost…
Introduction The financial industry drives the global economy, but its exposure to risks has…
