


A Comprehensive Guide to Snowpark – Part 1
Background
Snowpark is a new developer framework of Snowflake composed of a client-side library and a server-side sandbox. It enables users to build data-intensive applications using the popular programming language of their choice, such as Java, Python, or Scala. It also brings deeply integrated DataFrame-style programming to the above languages. With its rich set of APIs, Snowpark enables push-down optimization (moving code to where the data exists), thus unlocking the full potential of Snowflake’s cloud platform to build scalable, performant, and reliable data applications.
You can also create language-specific (Java, Python, or Scala) User-Defined Functions (UDFs) that return tabular results (UD(T)Fs) and Stored Procedures (SPs) for your custom logic that can be called from Snowpark.
Snowpark code execution: client side or server side?
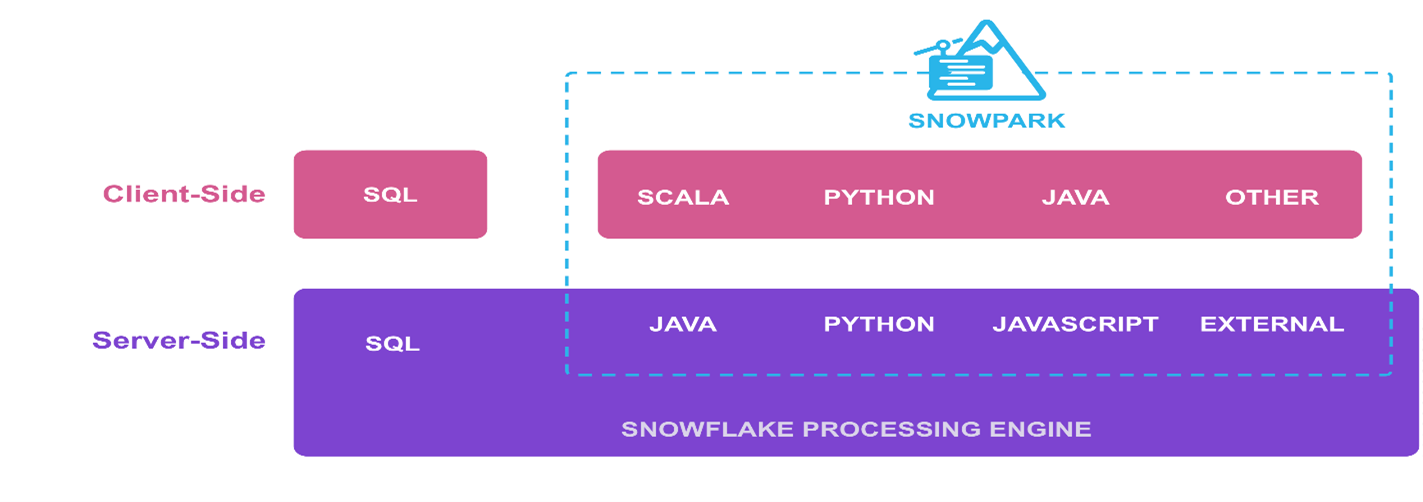
Fig 1: Client-side and server-side execution in Snowflake
In the context of Snowpark code execution, whether it should be executed on the client-side or the server-side is a common question.
For client-side execution, a Python environment (Python 3.8.* supported) with the installation of the Snowpark client library is needed. The Snowpark client library supplies APIs that help in the push-down of Snowflake SQL queries, data frame transformations, bundled SPs, and UD(T)Fs into Snowflake’s managed compute environment. As client-side execution uses a Python environment (hosted or local), it offers a simple and flexible method of connecting to external resources, such as making external API calls.
On the other hand, Snowpark has a server-side runtime, which allows the deployment of code in the form of Python SPs and UD(T)Fs directly into a Snowflake-managed runtime. Running Snowpark on the server side could simplify the management and maintenance of code, particularly if several users are accessing the same resources. Additionally, the overhead of maintaining a Python environment is eliminated in server-side execution.
Despite the fundamental differences between the two modes, the execution part at the Snowflake end is similar. Ultimately, whether to run Snowpark on the client or server side will depend on the specific use case and requirements.
Snowpark execution: What happens behind the scenes?
To better understand how Snowpark works, let’s examine its execution flow by breaking inputs down into three components:
- When Snowpark DataFrame operations are passed as input:
Snowpark DataFrames are the core abstraction of Snowpark, representing a set of data and providing methods (transformations) to operate on that data.
The execution process of the Snowpark DataFrame operations shown in Fig 2 from client-side is as follows:
As shown in Fig 2, the Snowpark client API library is the key component that acts like a translator, converting the DataFrame operations shown in Fig 3 into Snowflake SQL statements. As each DataFrame transformation is converted into equivalent Snowflake SQL, you can see in Fig 4 that the output SQL statements are highly nested and include multiple subqueries. When an action is invoked (Lazy Evaluation), the generated SQL statements are sent to the Snowflake warehouse for execution using either a Python or JDBC connector. These generated SQL queries are executed in the same way as any other Snowflake SQL queries, taking advantage of the performance and scale of the Snowflake SQL engine.
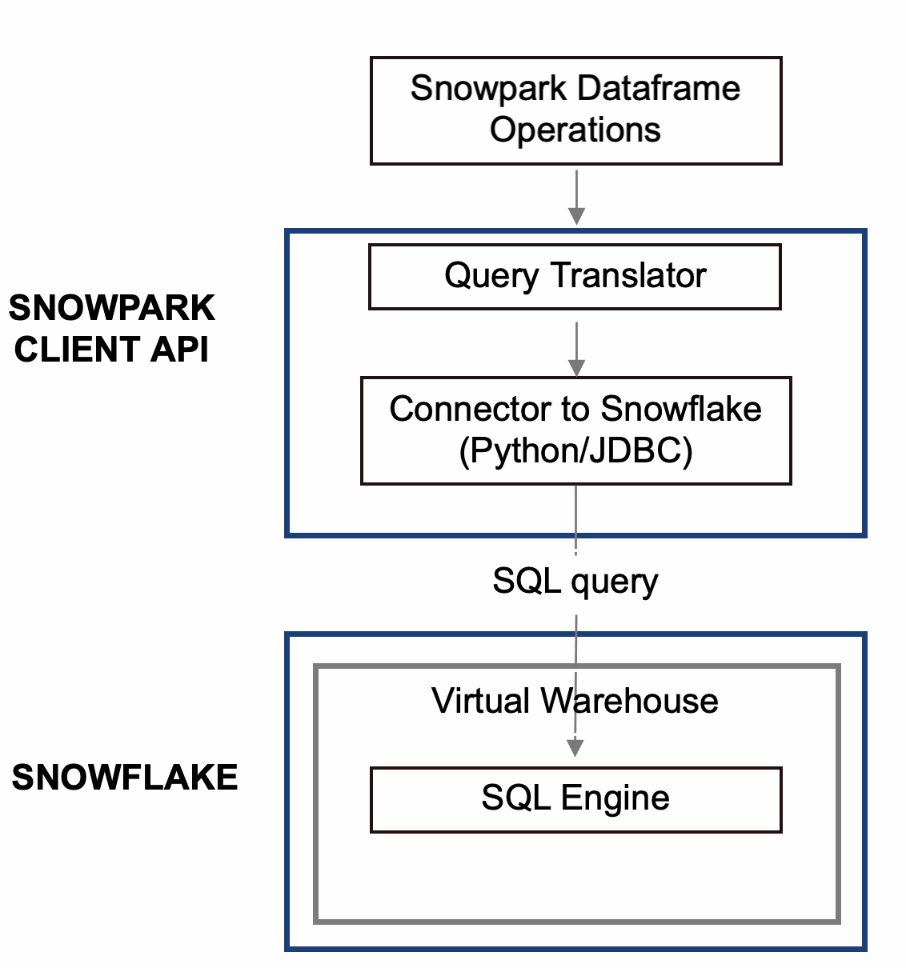
Fig 2: Snowpark DataFrame execution
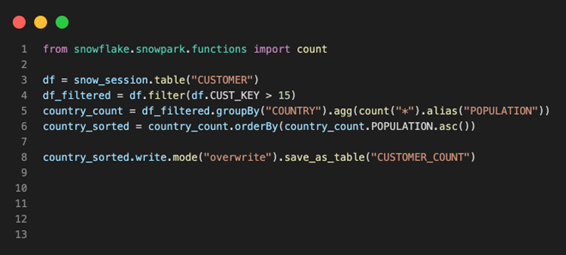
Fig 3: Snowpark DataFrame Operations
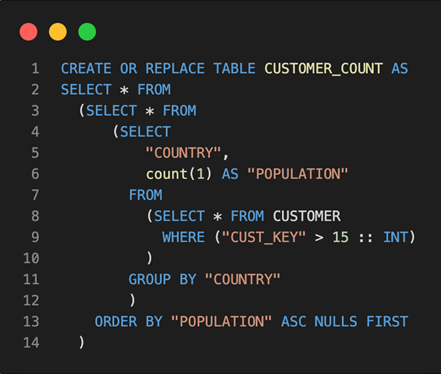
Fig 4: Generated Nested Snowflake SQL
In the above example, you can see that we have moved code to Snowflake by using push-down optimization, and data has never left Snowflake. Keeping the compute close to data also means you benefit from Snowflake’s data security and governance.
- When UD(T)Fs are passed as input:
When a user is trying to perform some operations which are not readily available using the built-in system-defined functions provided by Snowflake, the user can write their own functions called User Defined (Table) Functions, embedding custom logic into it. With Snowpark, you can create UD(T)Fs in the language of your choice (Python, Scala, Java). Once created, you can call these UD(T)Fs to process the data in your DataFrames and SQL statements.
The execution process of the Python UDF shown in Fig 5 from client-side is as follows:
As shown in Fig 5, the Snowpark client library uses an object serializer (cloudpickle package) that serializes the user’s UD(T)F code, which is shown in Fig 6, along with all necessary dependencies, into bytecode as shown in Fig 7. Using either a Python or Java Database Connectivity (JDBC) connector/API, the serialized code is sent to the Snowflake stage for later use.
When the time comes to execute the UD(T)F, Snowpark pulls the necessary dependencies from a secure Anaconda Snowflake channel (for Python UD(T)F) or Java Archives (JAR) files (for Scala or Java UD(T)F) and executes the code in the virtual warehouse within the Python Virtual Machine (PVM) or Java Virtual Machine (JVM) in Snowflake.
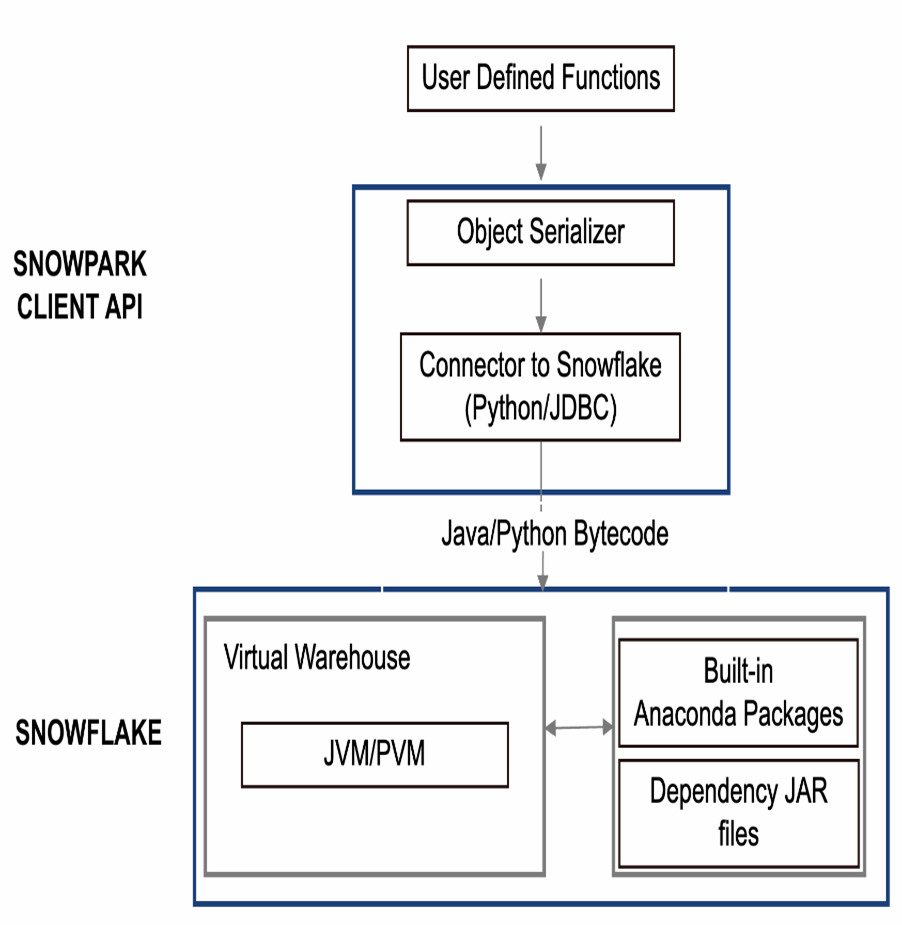
Fig 5: Snowpark UDF Execution
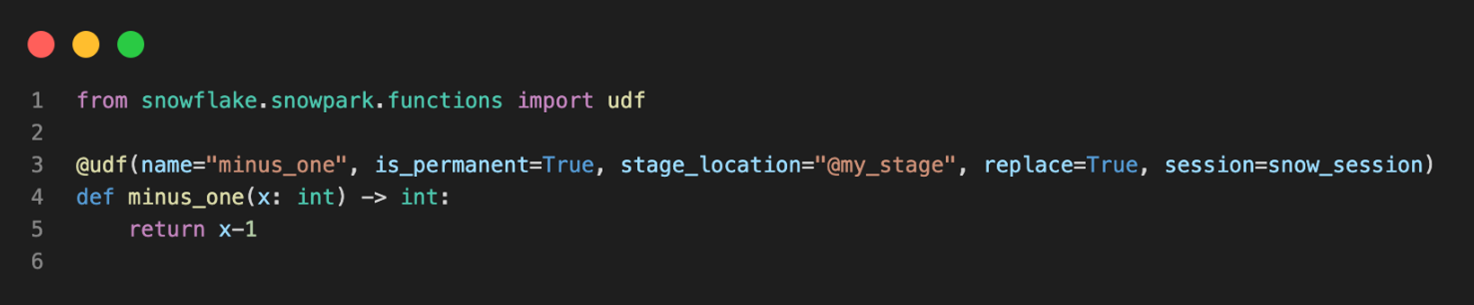
Fig 6: Snowpark UDF
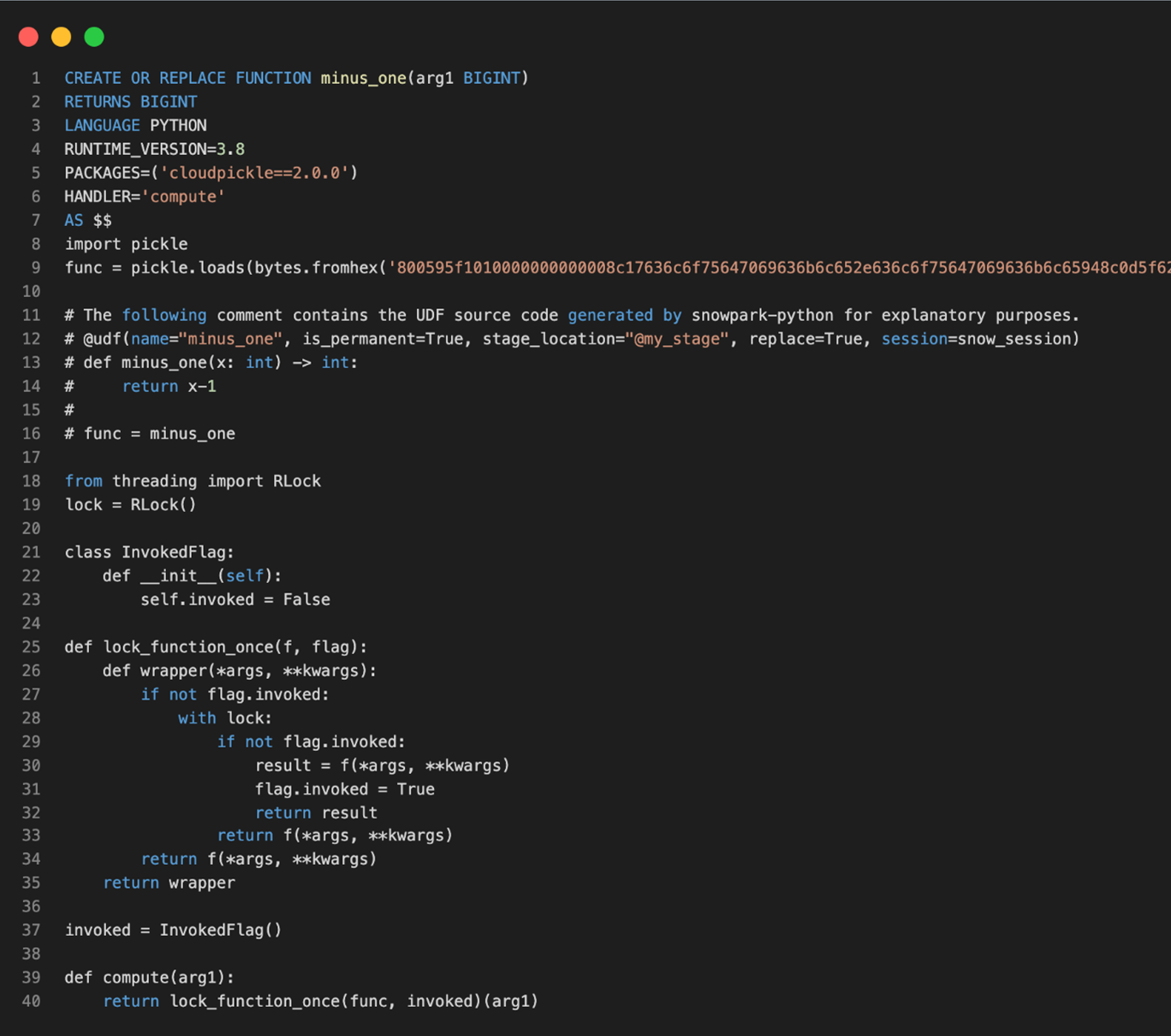
Fig 7: Generated UDF function
The above example shows that your custom logic inside UDF has been bundled and sent to Snowflake to run in a highly secure sandbox environment. This UDF can now be called inside SQL statements and DataFrames, and it is executed on the server, where the data is. As a result, the data doesn’t need to be transferred to the client for the function to process it.
The point to note here is that UD(T)Fs can only contain language-specific constructs inside them, you cannot access Snowpark DataFrames and Snowflake SQL statements inside the UD(T)Fs. If you look at Fig 5 closely, you can see that UD(T)Fs have no access to the Snowflake SQL engine but only to the Python and Java engines.
So, is there a way to wrap specific-language constructs, Snowpark DataFrames, and SQL statements into a single Snowflake object? Yes, this can be done using SPs.
- When SPs are passed as input:
With Snowpark, you can create SPs in the language of your choice (Python, Scala, Java). Snowpark SPs enable you to create reusable procedural code that can include complex business logic by combining Snowpark DataFrames, SQL statements, and language-specific constructs.
The execution process of the Python SP shown in Fig 8 from client-side is as follows:
As shown in Fig 8, the Snowpark client library uses an object serializer (cloudpickle package) that serializes the user’s custom code, as shown in Fig 9, along with all necessary dependencies, into bytecode, as shown in Fig10. Using either a Python or JDBC connector, the serialized code is sent to the Snowflake stage for later use.
When the time comes to execute the SP code, the Snowpark client library converts all the Snowpark DataFrame operations into equivalent SQL, and if any Snowflake SQL statements are present, they are run directly in the Snowflake SQL engine. For language-specific constructs, Snowpark pulls the necessary dependencies from a secure Anaconda Snowflake channel (for Python UD(T)F) or JAR files for Scala or Java UD(T)F) and executes the code within the Python Virtual Machine (PVM) or Java Virtual Machine (JVM) in Snowflake.
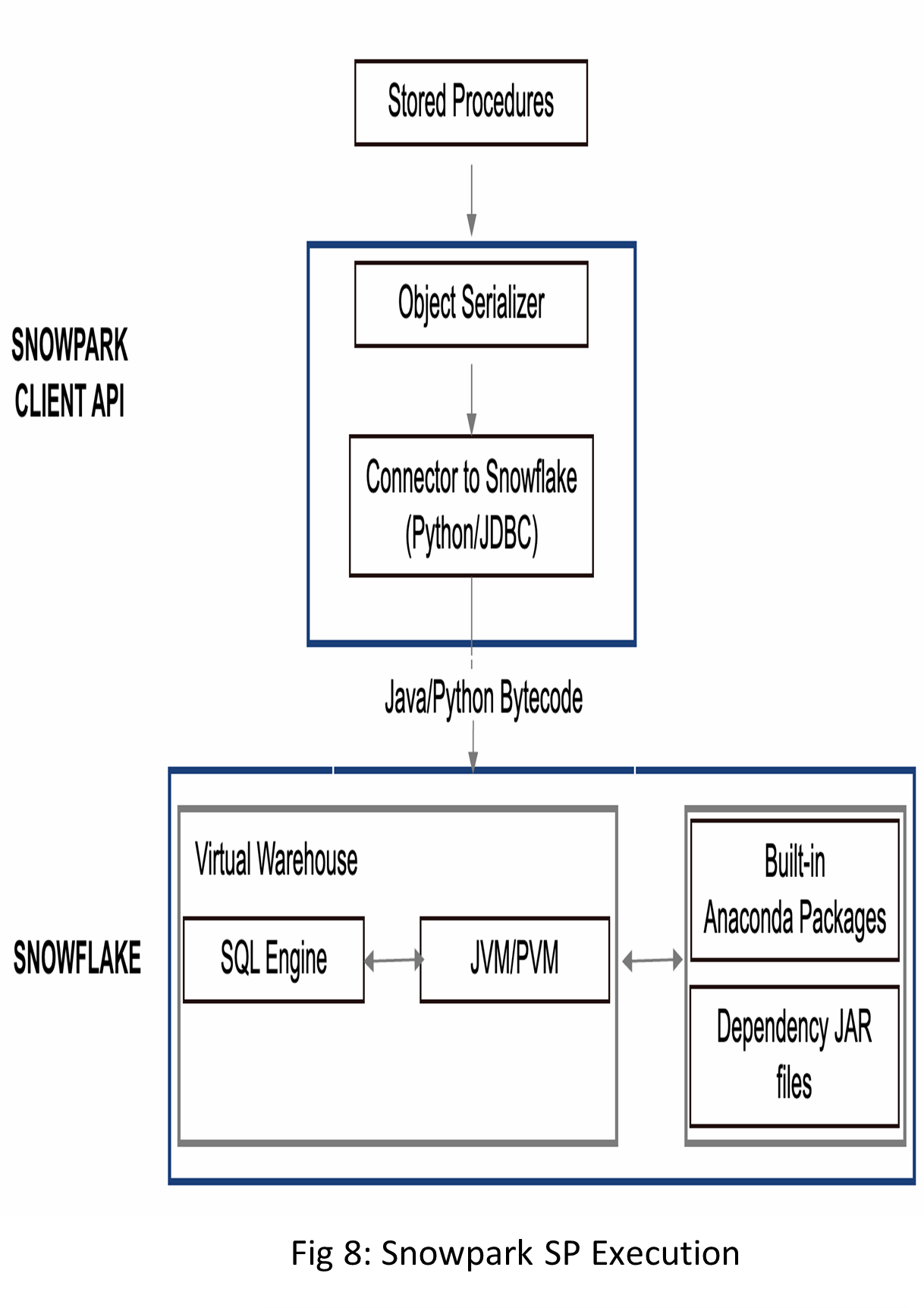
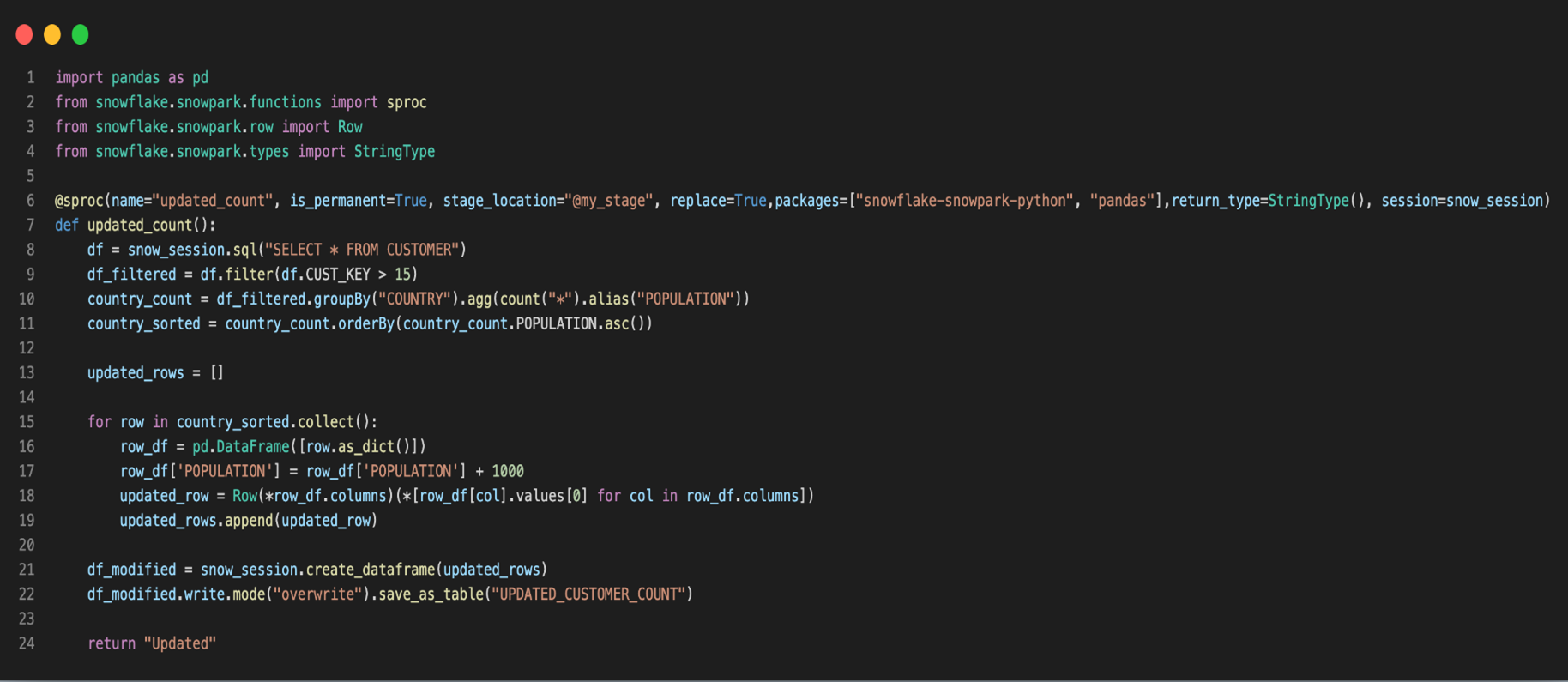
Fig 9: Snowpark SP
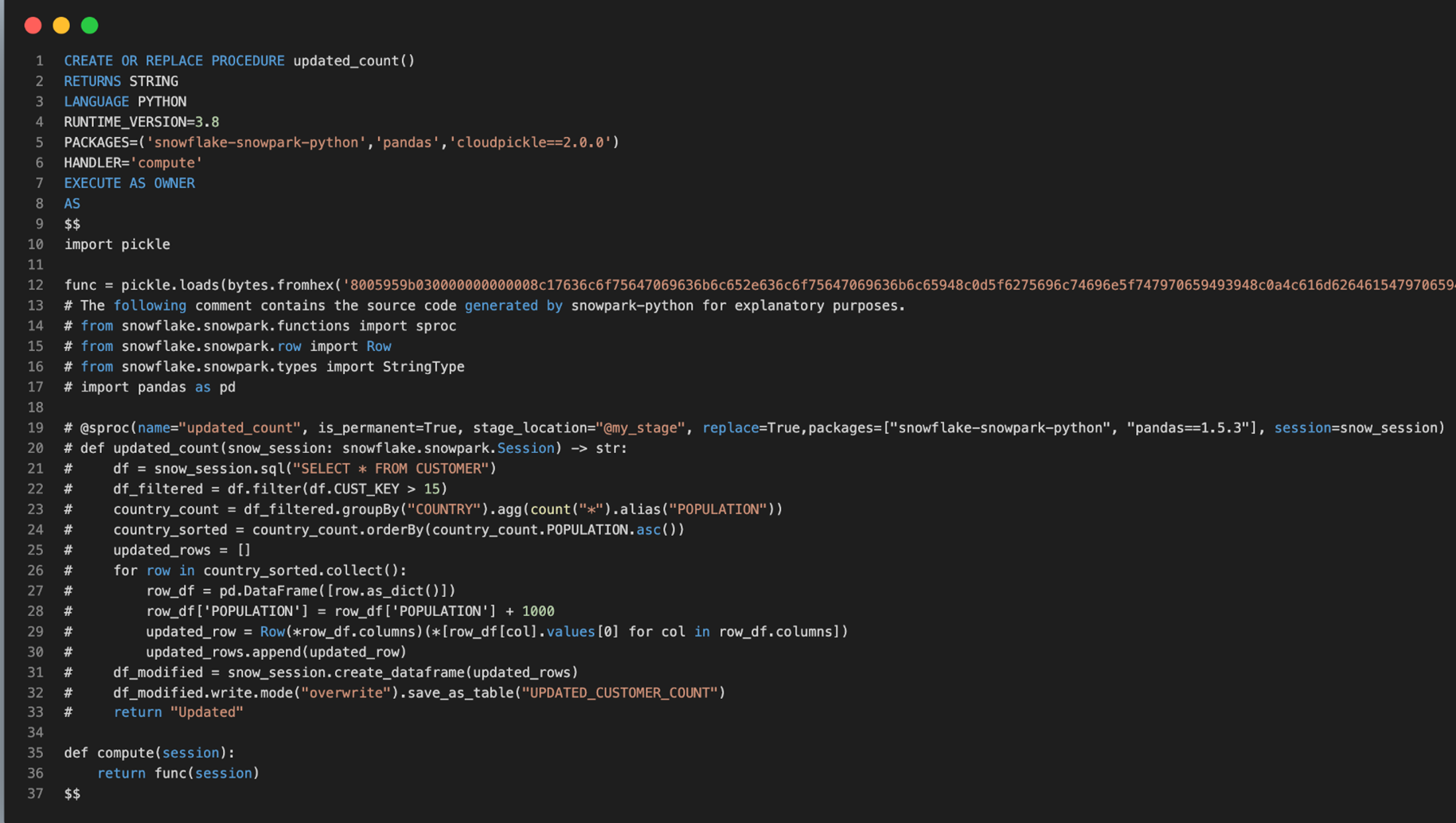
Fig 10: Generated Snowpark SP
The above provided example demonstrates the successful bundling and transmission of your customized logic within an SP (Stored Procedure) to Snowflake. This SP can now be invoked and executed on the server, where the data resides. Consequently, there is no need to transfer the data to the client for processing the function. Upon invoking the SP, the Snowflake-Snowpark-Python package (client library) is utilized to locate the Snowpark DataFrames and convert them into Snowflake SQL code. These DataFrames are then passed to the Snowflake SQL engine, benefiting from its performance and scalability. However, it’s important to note that language-specific constructs execute within secure a sandbox environment in a language-specific engine (PVM/JVM).
Conclusion
Snowpark is a versatile framework that empowers users to create data-intensive applications using their preferred programming language. It provides an array of useful features, such as push-down optimization, which enhances performance and scalability by executing code closer to the data. Additionally, Snowpark facilitates the development of user-defined functions (UDFs) and stored procedures (SPs) to encapsulate complex business logic.
We have also delved into different approaches for executing code with Snowpark, namely client-side execution and server-side execution. Choosing client-side execution is ideal for applications that necessitate access to external resources, while server-side execution is more suitable for applications that require multiple user management and maintenance.
Furthermore, we have explored the execution flow of Snowpark DataFrames, UD(T)Fs, and SPs. This knowledge proves valuable for developers planning to utilize Snowpark in their application development. It’s worth noting that UD(T)Fs have certain limitations as they only allow specific-language constructs. Nevertheless, prior to hastily embracing SPs for all use cases, it is imperative to carefully contemplate the constraints that come with them. In the following section of our upcoming blog, we will delve into these limitations and discuss strategies to overcome them.
References:
- Snowflake. (2023). Snowpark – Snowflake Documentation. Retrieved from https://docs.snowflake.com/en/developer-guide/snowpark/index
- Snowflake. (2022, January 10). Operationalizing Snowpark Python – Part One. Medium. Retrieved from https://medium.com/snowflake/operationalizing-snowpark-python-part-one-892fcb3abba1
- Snowflake Developers, Jan5, 2023, Snowpark Java & Python UDFs DEMO | Under The Hood, YouTube. Retrieved from https://www.youtube.com/watch?v=tT0jCX_Bjok
Blogger's Profile

Poorna Chand Addala
Senior Data Engineer, Snowflake Center of Excellence, LTIMindtree
Poorna is a valued member of LTIMindtree's Snowflake COE, where he serves as a Senior Data Engineer. He passionately invests his time in augmenting his expertise and refining his mastery in the realm of data engineering. Poorna's insatiable curiosity drives him to dive deep into his areas of interest, helping him stay at the forefront of advancements. He relishes the challenge of tackling complex technical problems and applies his creativity to find innovative solutions.
More from Poorna Chand Addala
Background: We’re glad to have you back for the second part of our extensive Snowpark guide.…
Latest Blogs
Introduction What if training powerful AI models didn’t have to be slow, expensive, or data-hungry?…
Pharmaceutical marketing has evolved significantly with digital platforms, but strict regulations…
Leveraging the right cloud technology with appropriate strategies can lead to significant cost…
Introduction The financial industry drives the global economy, but its exposure to risks has…
